
Krei epub arĥivon
Mi hodiaŭ parolos pri la transformadon de dosiero pdf al dosiero
epub por pli bone legi esperante. Mi montros ilon, kiun mi faris,
kaj klarigos kiel ĝi funkcias por faciligi, ke iu ajn povos adapti ĝin
por si mem. Ni uzos Emacs kaj elisp por kontroli tiun OCR
procezon, kiun ni bezonas por tiuj dosieroj, kiuj enhavas bildajn
skanadojn de teksto. La celo estas konverti nian pdf dosieron farita
de skanitaj bildoj al epub dosieron por pli bone legi en nia
inklibro aŭ tabuleto. Mi laboras per Linukso sed la rezulto estas
sendependa de la operaciumo kiun ni uzas. Mi iomete parolos pri kiuj
programoj mi uzas por tiuj laboroj.
Mi proponis multe pli legi por praktiki Esperanton sed ne ĉiam oni
trovas interesan kaj oportunan legadon. Mi parolas precipe pri
oportuna. Rete oni trovas multajn dosierojn, kutime je pdf por
praktiki la legadon esperante. Kiam la pdf dosieron enhavas veran
tekston estas pli facila konverti la dosieron. Eble nur devas
transdoni al teksto kaj poste al html, epub aŭ alia ajn speco de
dosiero ke ni bezonas.
Ni havas:

sed ni volas:

por povi legi tiel:

Do, ni bezonas kelkajn ilojn por fari nian laboron:
- Konvertilo por bildformato: ni uzos la ilon
pdfimageskiu prenas la paĝojn de lapdfkaj skribas en sendependaj bildoj. - OCR ilo: ni uzos
tesseract-ocr, kiu permesas traduki per multaj lingvoj, inter ili Esperanto. - Emacs por uzi ĝian skriptan lingvaĵon.
Ankaŭ ni povas fari la laboron sen Emacs nur per bash, sed finfine
ni bezonos ajnan skriptan lingvaĵon. Kial mi uzas elisp? Ĉar tiu ilo
estas taŭga por labori kun tekstojn kaj havas tre potenca ilo por
labori kun dokumentoj: org-mode.
Aliflanke ni devas ankaŭ preni la enajn bildojn por la lasta paŝo de nia procezo.
Konverti dosieron
Mi klarigos kiel mi faras por konverti pezan pdf, farita de skanitaj
bildoj, ĝis atingi sufiĉan bonan epub por legi per mia bitlibro.
Tiu legado estas pli agrabla ol legi la originan pdf per tiu ilo.
La teksto aranĝas al ekrano kaj faciligas bonan sperton de legado.
Ni povas fari la laboron mane:
Preni la bildon de la
pdfdosiero:pdfimages -png -f 1 -l 10 dosiero.pdf paĝo
Tiu kreas bildoj de la
paĝo-001.pngalpaĝo-010.png.Konverti la bildoj en teksto:
tesseract -l epo paĝo-001.png paĝo-001
Tiu metas la teksto legita de la bildo
paĝo-001.pngenpaĝo-001.txt. La formo-l epopor Esperanto. Vi povas scii la lingvojn kiu komprenastesseractper la komandotesseract --listlangs.- Aranĝi ĉiu la dosieroj
txten unu sola dosiero. Pro tiu ni povas uzi teksredaktilon.
Tio estas teda, paĝo al paĝo kaj ankaŭ ni povas enmeti erarojn, ripeti ajnan paĝon, forgesi alian, ktp. Ankaŭ, finfine ni devas pritrakti la tekston per teksredaktilo... do, kial ni ne uzas teksredaktilon kiu havas skriptan lingvon por aŭtomatigi la taskon. Mi uzas Emacs.
Kodo
Mi skribis la sekvantan kodon por aŭtomatigi la proceson en komandara
dosiero nomita konverti-ocr.el:
;;; konverti-ocr.el ;; La variabloj de la procezo. (defvar dosiero "" "Variablo kiu enhavas la nomon de la dosiero por konverti.") (defvar komenco 0 "Paĝa numero kie komencas la procezon.") (defvar fino 0 "Paĝa numero kie finas la procezon.") (defvar lingvo "" "Lingvo de la listo `tesseract --listlangs`") (defun komencu () "Sarĝu la variabloj por la procezo." (setq dosiero (org-entry-get (point) "dosiero")) (setq komenco (string-to-number (org-entry-get (point) "de"))) (setq fino (string-to-number (org-entry-get (point) "gxis"))) (setq lingvo (org-entry-get (point) "lingvo"))) (defun pritrakti-paĝo (num) "Enmeti la tekston kreata en la /punkto/." (message "Konverti paĝon %s" num) ;; Habigi la bildon (call-process-shell-command (format "pdfimages -png -f %d -l %d %s paĝo" num num dosiero)) ;; Habigi la tekston (call-process-shell-command (format "tesseract -l %s paĝo-000.png temporal" lingvo)) ;; Enmeti la tekston en la /punkto/ (insert-file-contents "temporal.txt") ;; Forigi la temapajn dosierojn (shell-command "rm paĝo-000.png temporal.txt")) (defun pritrakti-ocr () "Lanĉas la taskon por konverti bildan pdf al teksto." (interactive) (komencu) ; Establece las variables globales (mapc 'pritrakti-paĝo (number-sequence fino komenco -1)))
Mi preparas la dosieron kie ni enmetos la tekston de la konvertado:
* Prologo :PROPERTIES: :de: 20 :gxis: 34 :dosiero: ./la-mastro-de-la-ringoj.pdf :lingvo: epo :END:
Ni devas rimarki ke en la PROPERTIES difinoj ne povas uzi ĉapelitajn
literiojn.
Por fari tion, ni devas unue voki nian kodon per load-file
konveri-ocr.el. Ĉi tiu komando en Emacs legas la kodon kaj poste ni
povos uzi la komandon M-x pritrakti-ocr. Nian kodon komencos leganta
de la paĝo 34 ĝis la 20. Tiel ĝi faras por korekte ordigi la paĝon en
la dosieron.
La rezulton estas:

Kiel ni povas vidi, la rezulto estas sufiĉe bona por komenci labori. Ni devas forigi la paĝan numeron inter la teksto, korekti erarajn literojn. Tiu estas la plej teda tasko por konverti librojn. Sed Emacs helpas min ĉar oni povas uzi aŭtokorektadon de teksto por Esperanto. Sed la laboro de purigo neniam finiĝas, kiel ni vidos je la fino.
Kiam la teksto estas sufiĉe purigita (aŭ mi pensas tion) mi konvertas
la dosieron, en nia ekzemplo nomita probo-dosieron.org al html
aranĝo. Emacs faciligas tiun taskon: mi nur devas uzi la komandon
C-c C-e h h kaj ĝi kreos la dosieron probo-dosieon.html. Poste,
tiuj html dosieroj poste estos aranĝitaj en la epub dosiero.
Preti fontojn
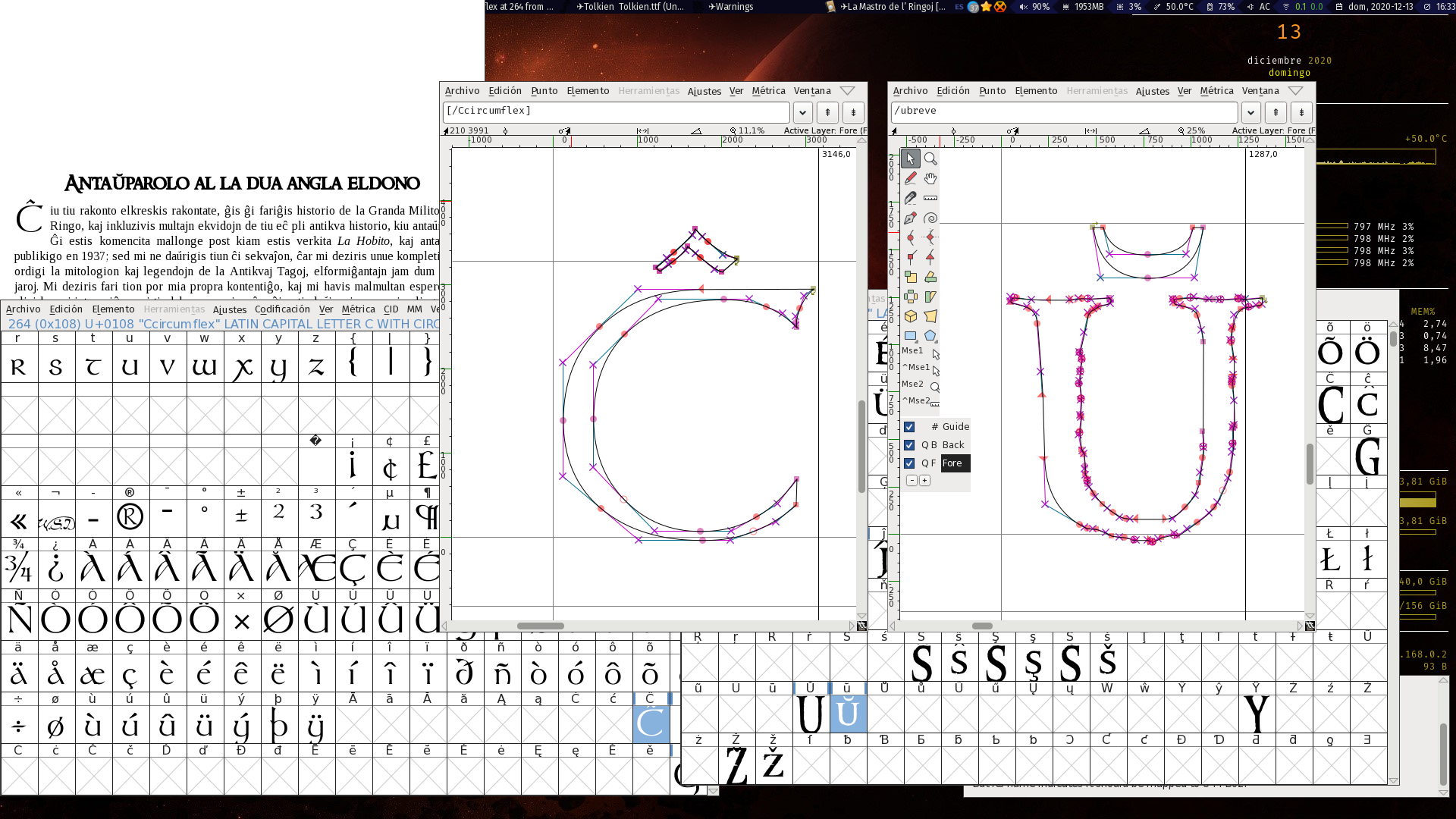
Eble, mi povus legi la tekston sen plia laboro, sed mi estas sibarita leganto kaj ne nur volas, sed bezonas, belajn librojn. Do mi devas pli labori por fari ilin.
La tutaj ekzemploj de ĉi tiu artikolo estas prenataj de mia laboro por
aranĝi la mastro de la ringoj kiel epub dosiero por plezure legi
per mia bitlibro. Por tiu projekto mi serĉis literojn ĉe
https://www.dafont.com tiujn tiparojn, kiuj povas taŭgi en ĝi. Sed la
tiparo kiu ŝatas al mi ne havas ĉapelitajn literojn kaj tiuj kiuj
havas ĉapelitaj literojn ne taŭgas al projekto.
Do, mi elektis miajn plej ŝatatajn literojn kaj uzis fontforge por
fari en ĝi la literojn mankantaj. Ne estas komplika afero, mi nur
kopiis literojn kaj signojn kiuj jam ekzistas en la fonto por aranĝi
la ĉapelitaj. Tiel ni povas krei paĝojn, titolojn kaj tekstojn per
ili.

aŭ

aŭ

Por tiuj paĝoj estas pli grava nia laboro per css kaj html ol per
la fontoj. Pro tio ni atingas la lastan laboron por krei nian
bitlibron.
Aranĝi dosieron

Per la pasintaj laboroj ni kreis html dosierojn, pretis bildojn kaj
fontojn, kaj nun ni devas aranĝi la epub dosieron. Pro tiu laboro mi
uzas la programon sigil, kiel oni povas vidi en la antaŭa bildo.
Antaŭ, kiam ni konvertis la bildojn al tekstoj, ni kreis la diversajn
dosierojn html. Nun ni devas porti ene ĉi tiujn dosierojn al
epub. Por ordigi la diversajn partojn de la libro ni havas la listo
kiu ni povas vidi maldekstre en la bildo. Movi la dosieron supren aŭ
suben estas tiel simple kiel treni la etikedon per la muso.
Fine, ni devas krei la metadatumojn, minimune la aŭtoro kaj la
titolo sed estas grava kompletigi tiun informon tiom, kiom ni
povos. Ankaŭ ni bezonos tabelenhavon, kaj sigil havas ilon por krei
tiun tabelon.
La lasta tasko estas malrapide legi kaj repurigi la erarojn. Vortoj kiuj aperas kunigitaj aŭ tiu, kiu aperas apartigita. Erarojn, misaj literoj, strangaj signoj kiujn ni ne vidis antaŭe, ktp.
Konkludo
Finfine, mi havas mian dosieron enmetita en mia bitlibro. Mi nun komencas la legado, la lasta legado kaj mi registros la erarojn kiujn mi trovos. Poste mi plibonigos la eldonon kaj mi gardos ĝin por plezure legi kiam mi volos.




Comentarios