
Un poco más sobre magit
Hace tiempo que vengo usando magit como una de esas cosas que
proporciona Emacs para facilitarnos la vida. Aún hace más tiempo
que, también, vengo tropezando con git y aunque lo uso para casi
todo, mi torpeza habitual evita que termine de entender exactamente
cómo funciona y cómo puedo aprovecharlo del todo. Por otro lado,
también he de confesar que desconozco muchos de sus comandos y
posibilidades. Sin embargo, con el uso normal que vengo haciendo
últimamente de git he ido aprendiendo algunas pocas cosas. Con uso
normal me refiero a que últimamente lo estoy utilizando que para lo
que fue diseñado: para gestionar el código y sus versiones, con sus
ramas de desarrollo y demás chismáticos.
Hasta ahora mis repositorios venían siendo muy lineales, como el de la
contabilidad que llevo con ledger-cli, básicamente es una sola rama
master donde voy anotando gastos, facturas, ingresos y demás
apuntes. Vale que me permite saber no sólo cuándo se ha hecho un pago
o cobrado una factura, sino también, git me permite saber cuándo lo
he contabilizado y, ésto me ha ahorrado algún que otro quebradero de
cabeza buscando ese apunte en el que me confundí al escribir los
decimales, simplemente acotando cuándo dejaron de cuadrar las cuentas.
Sin embargo, eso aunque es utilizar git, no es un uso completo. Y no
es que haya avanzado mucho, pero he aprendido unas pocas cosas más y,
sobre todo, las he aprendido a hacer también utilizando magit.
Ya he hablado en alguna ocasión sobre magit y sus bondades, pero me
vais a permitir que me repita y hable un poco más sobre ello, desde
cero y haciendo un pequeño ejemplo de cómo puede ir el funcionamiento
de un repositorio desde su creación. Porque hay quien, no siendo
programador, quiere tener una idea más visual de lo que le hablo y me
ha preguntado directamente.
Los que vengan a este artículo y ya utilicen git quizá se aburran un
poco de mis explicaciones para novatos. Pero el caso es que escribo
esto para quien me ha preguntado y está recién llegado al control de
versiones.
Iniciar repositorio
Pues el inicio es sencillo si queremos iniciar un pequeño repositorio:
magit-init pregunta dónde y le damos un path donde debe iniciarlo:

Si le hemos dado un path que no existe, lo crea y genera dentro de
él un repositorio git vacío... aunque propone algo para rellenarlo
de momento:

En el caso del ejemplo, he creado un repositorio en un directorio
llamado ~/proyectos/repositorio-prueba. Está vacío, no he escrito
nada, no hay ningún fichero ni contiene nada. Si miramos el directorio
veremos que contiene sólo el subdirectorio oculto .git con los datos
del repositorio.
A ese repositorio le vamos a dar otro repositorio origen, que podría ser el compartido. Me vais a permitir que yo utilice para las pruebas directorios locales del ordenador, pero cuando se crea un repositorio bare, pregunta por la localización del mismo: podemos seleccionar entre una URL, un directorio o un repositorio local.

y nos permite clonarlo en cualquier sitio. Para las pruebas lo he
clonado en ~/repositorio-prueba... y el resultado es el siguiente:
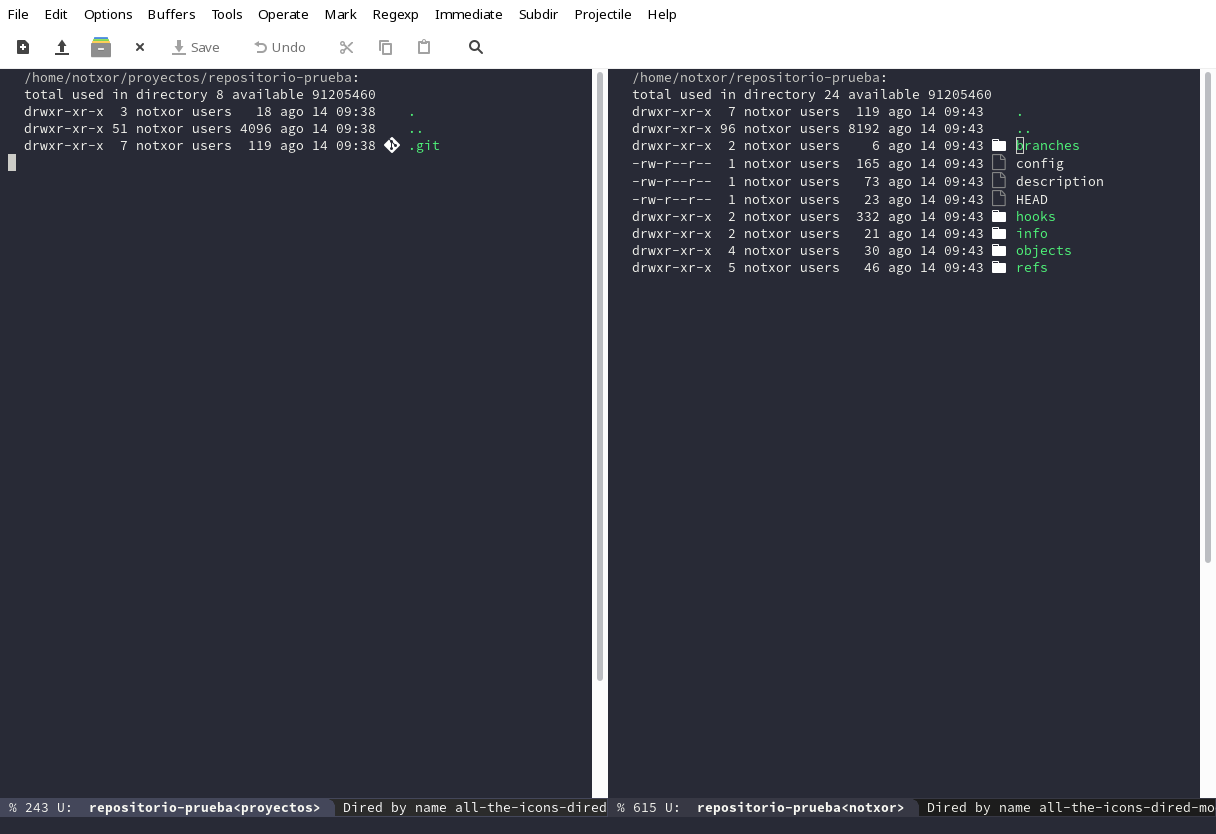
Como se puede apreciar en la imagen, a la derecha tenemos un
repositorio bare (es decir, por explicarlo de otra manera para quien
aún sepa menos que yo sobre git, no tiene los ficheros de código
directamente, pero guarda los objetos que lo contienen). Este tipo de
repositorios se utilizan, no para editar código sino para guardarlo y
por tanto suelen tener la función de repositorios remotos. De hecho,
magit preguntará al crear el bare si lo queremos usar como
origin ─que es el nombre que se le da normalmente al repositorio
remoto original─.
Modificar algo en el repositorio
Para nuestro ejemplo necesitamos crear algún fichero que gestionar con
nuestro flamante repositorio. Así pues, vamos a crear un fichero de
texto en nuestro directorio de trabajo (que vuelvo a recordar que es
~/proyectos/repositorio-prueba, por si alguien se despista).
Una vez creado el texto, que no tiene por qué ser muy largo para hacer
las pruebas, vamos a incorporarlo a nuestro repositorio. Primero, al
acceder a magit nos dice que el fichero no está siendo gestionado
por git.

Bien, situándonos en la línea de nuestro fichero, el que queremos
añadir pulsamos s (stage):
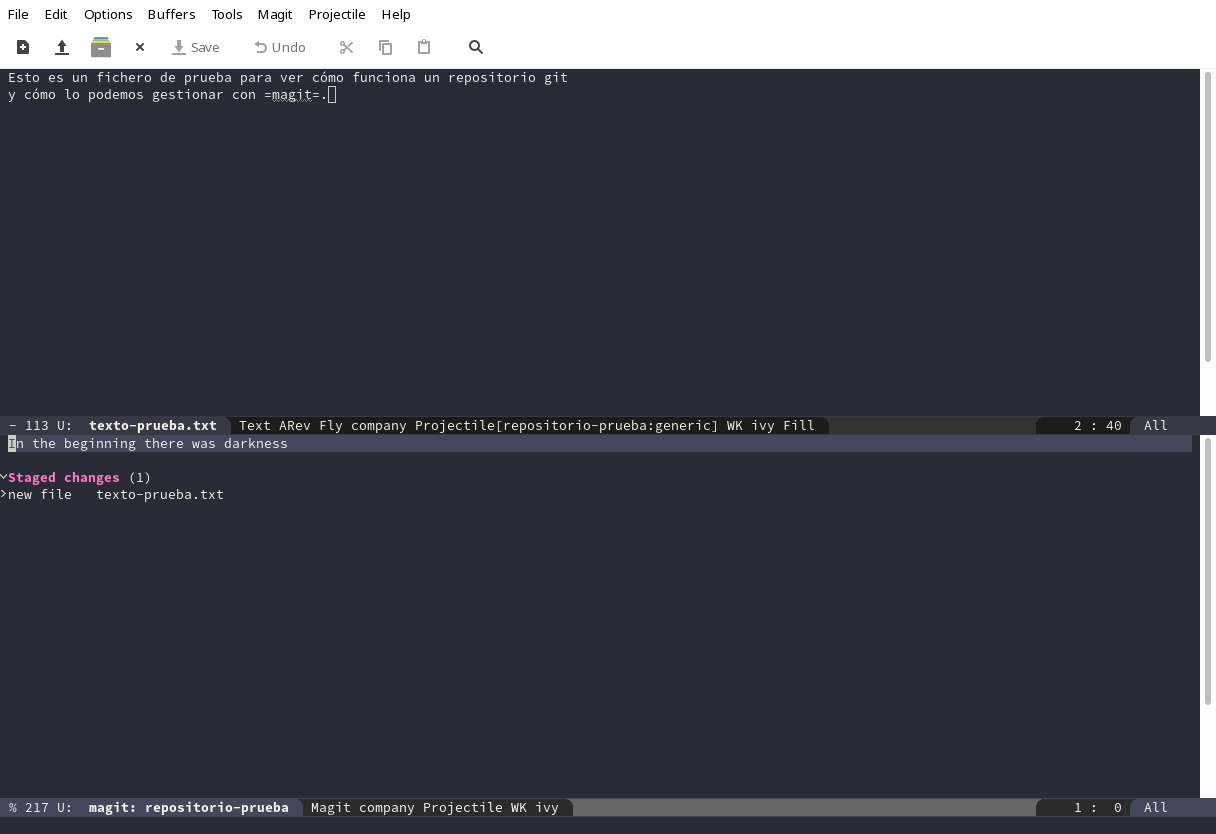
Ya tenemos los cambios aceptados, vamos a decirle al repositorio
local que los guarde haciendo un commit. Para eso, siguiendo en la
ventana de magit pulsamos cc (sí, dos veces c, la primer c
muestra el menú de commit y la segunda inicia el commit, porque en
este ejemplo no necesitamos otras opciones) y nos mostrará una ventana
como ésta o similar:

Como podemos ver, nos muestra una ventana de diff donde podemos ver
los cambios que vamos a incluir en el commit y, en este caso abajo,
nos pide un texto para el commit. Sólo tenemos que introducir el
texto explicativo de lo que sea que estamos subiendo y cuando acabemos
pulsar C-c C-c... si en este paso nos arrepentimos, por ejemplo,
porque se nos ha olvidado añadir algo o nos damos cuenta de que algo
no anda bien, podemos pulsar C-c C-k y se detiene el proceso del
commit. También lo podemos hacer por partes, dividir los cambios en
diversos commits, etc., pero lo dejamos para los usuarios pro. De
momento, todo anda bien así que aceptamos los cambios:

Podemos ver, que por defecto, nos encontramos en la rama master (y
recordad, que si sólo aparece la cabecera Recent commits podéis
desplegar la lista pulsando <TAB> sobre ella).
Hasta ahora los cambios sólo han afectado al repositorio local. Pero en la primera parte del artículo, habíamos creado un bare con la intención de utilizarlo de remoto. Y nuestros cambios están muy bien en nuestro repositorio local, pero si compartimos el remoto con alguien más, necesitamos que esos colaboradores puedan acceder a ellos.
Añadir un repositorio remoto
Para añadir un repositorio remoto utilizamos el comando
magit-remote-add, nos pedirá una URL. En nuestro caso, creamos en
pasos anteriores un repositorio bare en ~/repositorio-prueba para
que nos sirva de remoto. Nos preguntará también por un nombre y el más
preferible para el repositorio principal suele ser origin, aunque
podemos utilizar otros.
Sincronizar los dos repositorios
Para subir cambios a un repositorio remoto pulsamos P, o S-p, si lo
preferís así... vamos lo que viene a ser una pe con mayúsculas. Nos
aparecerá un diálogo como el siguiente:
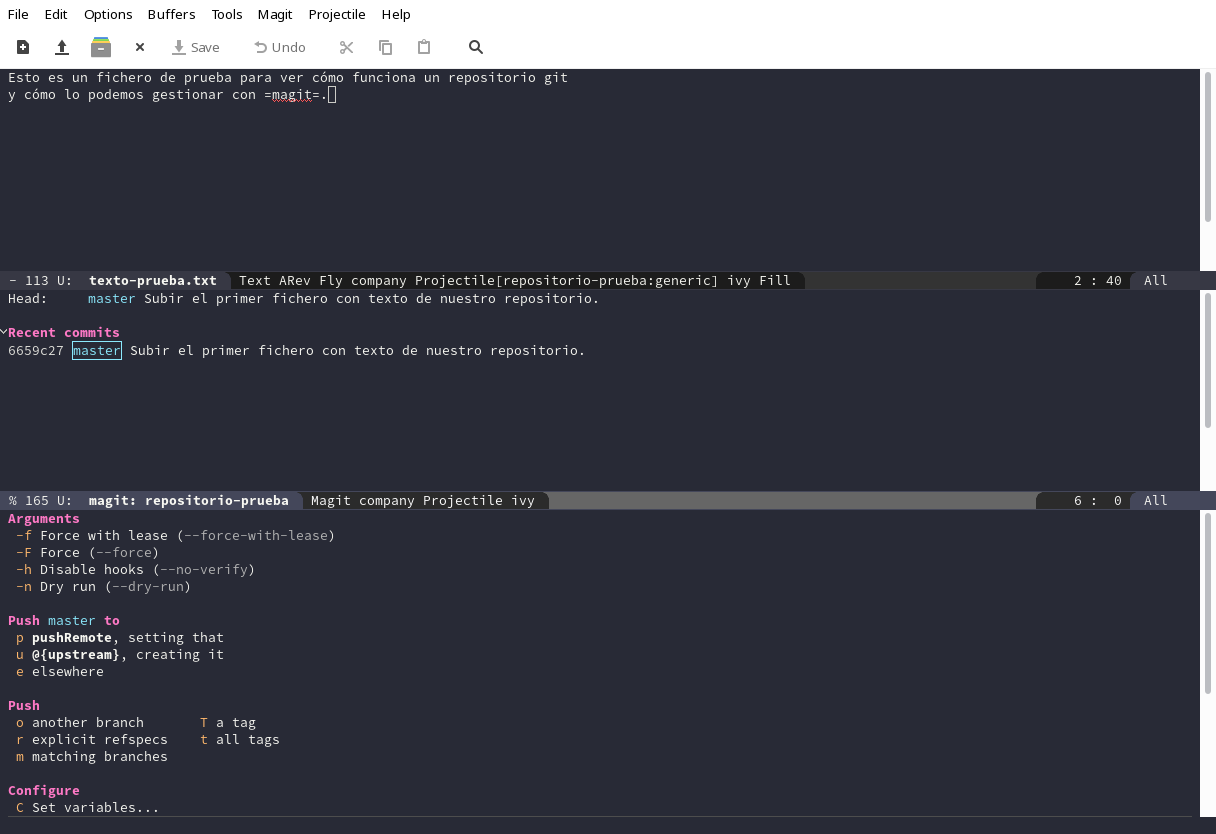
Es el primer push que vamos a hacer y necesitamos fijar dónde, vamos
a pulsar u, nos preguntará algo como Set upstream of master and
push there y puesto que ya habíamos establecido el repositorio
remoto con el nombre origin nos muestra lo siguiente:

Y al pulsar <RET>:

Como vemos, nuestro HEAD está en el mismo commit que el
origin/master y, además, en los commits recientes nos marca ambos
en el mismo lugar.
Quizá si hacemos cambios podemos ver la diferencia cuando dejan de
estar sincronizados. Escribo un par de líneas más y repito el proceso
del commit en local para ver la diferencia:

Como vemos, nuestro HEAD local está en un commit mientras que el
repositorio remoto está en el anterior. Magit además nos avisa de
que hay algunos commits, ─en concreto (1), dice─ que están sin
subir al remoto. ¿Cómo los sincronizamos de nuevo? Pues como hicimos
antes, pero más fácil: P u... si nuestro remoto es de verdad y nos
conectamos a él por SSH o por cualquier otro método, nos pedirá la
contraseña correspondiente y todo vuelve a estar sincronizado.
Ramas
El proceso hasta ahora ha sido sencillo y lineal, crear un
repositorio, hacer modificaciones, subir cambios al remoto... para
muchas cosas sirve, pero es posible que necesitemos más potencia a
esto de los cambios. ¿Qué ocurre si necesitamos probar algo pero
sabemos que los cambios que debemos hacer para probarlo son difíciles
de revertir? Estaría bien, poder hacer pruebas y sin embargo, que el
código no se vea afectado por dichas pruebas hasta estar seguros de
que es lo que queremos y funcionan. Para eso se inventaron las ramas
(branch en inglés). Otro ejemplo, que podríamos considerar con ramas
fácilmente es uno que en la vida real nos da mucho trabajo: cuando
tenemos entre manos un informe y nos piden que modifiquemos algo para
presentarlo en otro lugar o a otra institución o a otro cliente. El
instinto básico copiaría el mismo informe en otro sitio, con otro
nombre, se harían los cambios necesarios y se guardarían en otro
sitio, con otro nombre. Pero, si hubiera cambios en algún apartado
común tendrías que estar buscando en cada una de esas copias y
haciendo los cambios que correspondan. Bien, un control de versiones
como git nos facilitará mucho ese versionado, atendiendo a las
ramas, cada informe estaría en una rama con nombre adecuado. Los
aparados de cada uno en su correspondiente rama, y los generales en la
rama master. Y así es cómo estoy gestionando estas cosas ahora: los
contenidos suelo hacerlos en org-mode o LaTeX, según el caso, pero
ambos son texto plano que puedo meter en un repositorio, aunque sea
local o en mi nube particular o en un repositorio compartido (si es
el caso).
Crear una rama
En el momento en que creamos una rama, todos los cambios que hagamos
en ella no afectarán al tronco del que nace. Vamos a crear en nuestro
proyecto una rama con magit, paso a paso, como hemos venido haciendo
hasta ahora:
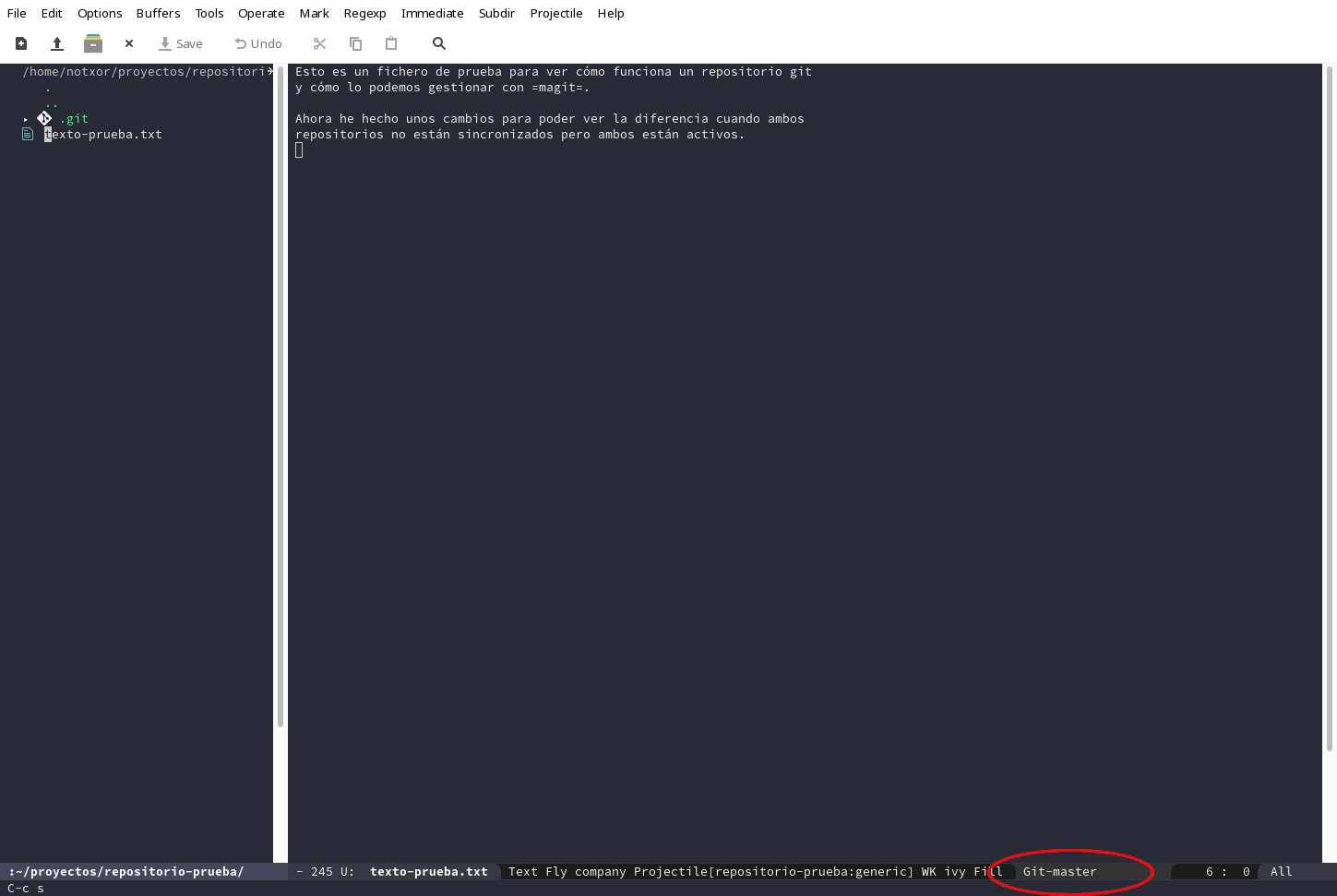
Si nos fijamos en la línea de estado, nos especifica que estamos en
Git-master. A mí me gusta crear una rama y cambiarme a ella
inmediatamente, por eso suelo utilizar magit-branch-and-checkout más
que magit-branch-create... pero se puede crear la rama y permanecer
en la anterior, hacer lo que se necesite y cambiar a la rama creada
posteriormente. Cuando iniciamos el comando, después de solicitar la
creación de la rama, nos preguntará en cuál otra queremos basar la
nueva rama:
No tenemos mucho donde elegir, sólo una: master. Así pues, la
seleccionamos y después nos preguntará por el nombre de la nueva
rama. En mi caso he seleccionado uno tan descriptivo como
rama-nueva. Pero recuerda que en el caso de ser un repositorio de
trabajo, es recomendable utilizar nombres más descriptivos para no
liarnos. Sobre todo si se van a utilizar muchas ramas.

¿Cómo afecta todo esto a nuestro repositorio? Pues lo vemos en la siguiente imagen:
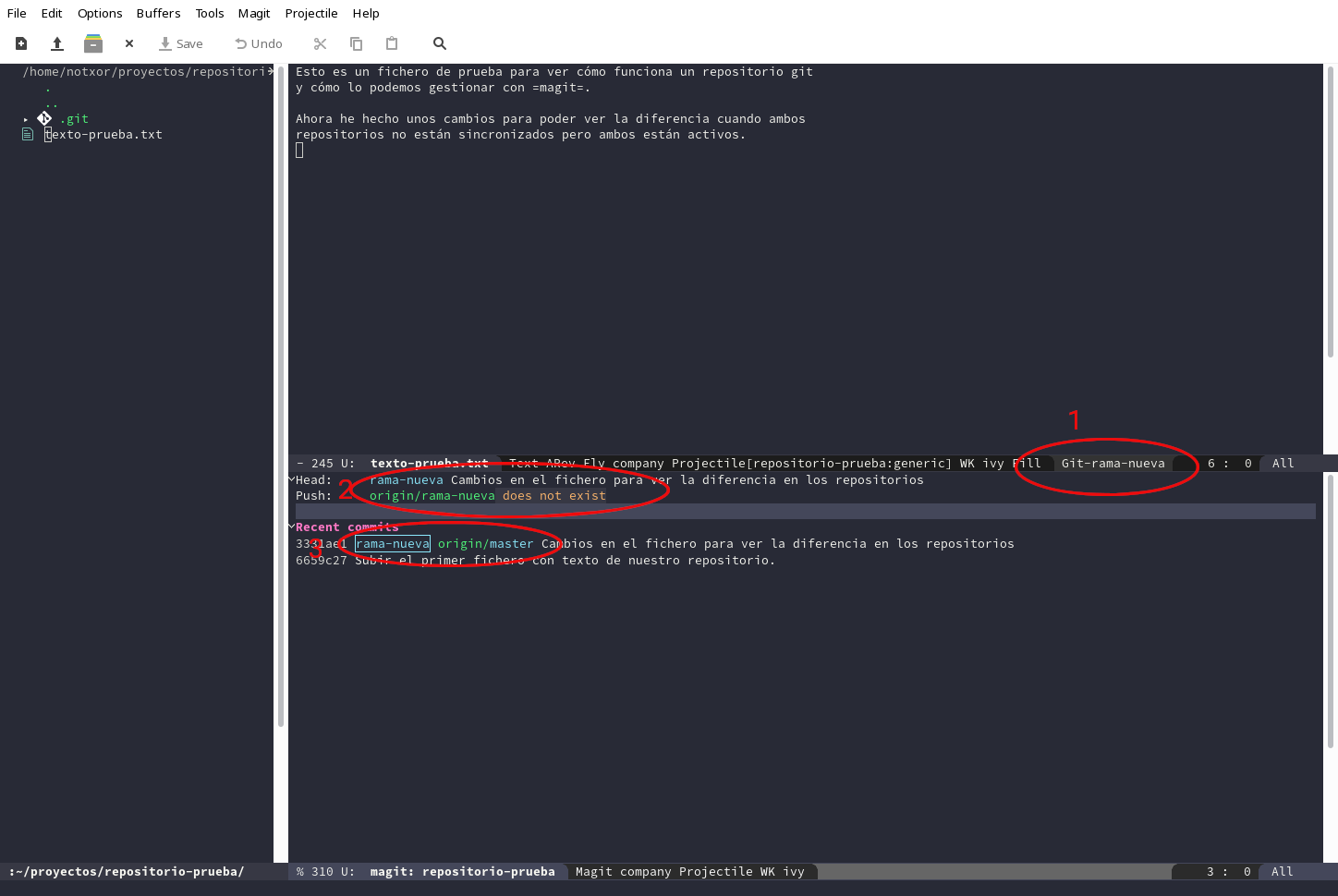
Los cambios remarcables son sencillos:
- La barra de estado nos avisa que estamos en la rama
Git-nueva-rama. - Nuestro
HEADestá ennueva-ramay también nos avisa de que no existe la rama remotaorigin/nueva-rama. - El commit actual es el mismo en el que creamos la rama. Así que
ahora mismo el estado de
rama-actualcoincide con las ramasmasteryorigin/master, porque es en el que hemos basado la rama nueva.
Para que todo fluya, vamos a hacer cambios en esta rama y compararemos qué ocurre con esos cambios. Por ejemplo, vamos a crear otro fichero de texto nuevo y a añadirlo al proyecto.
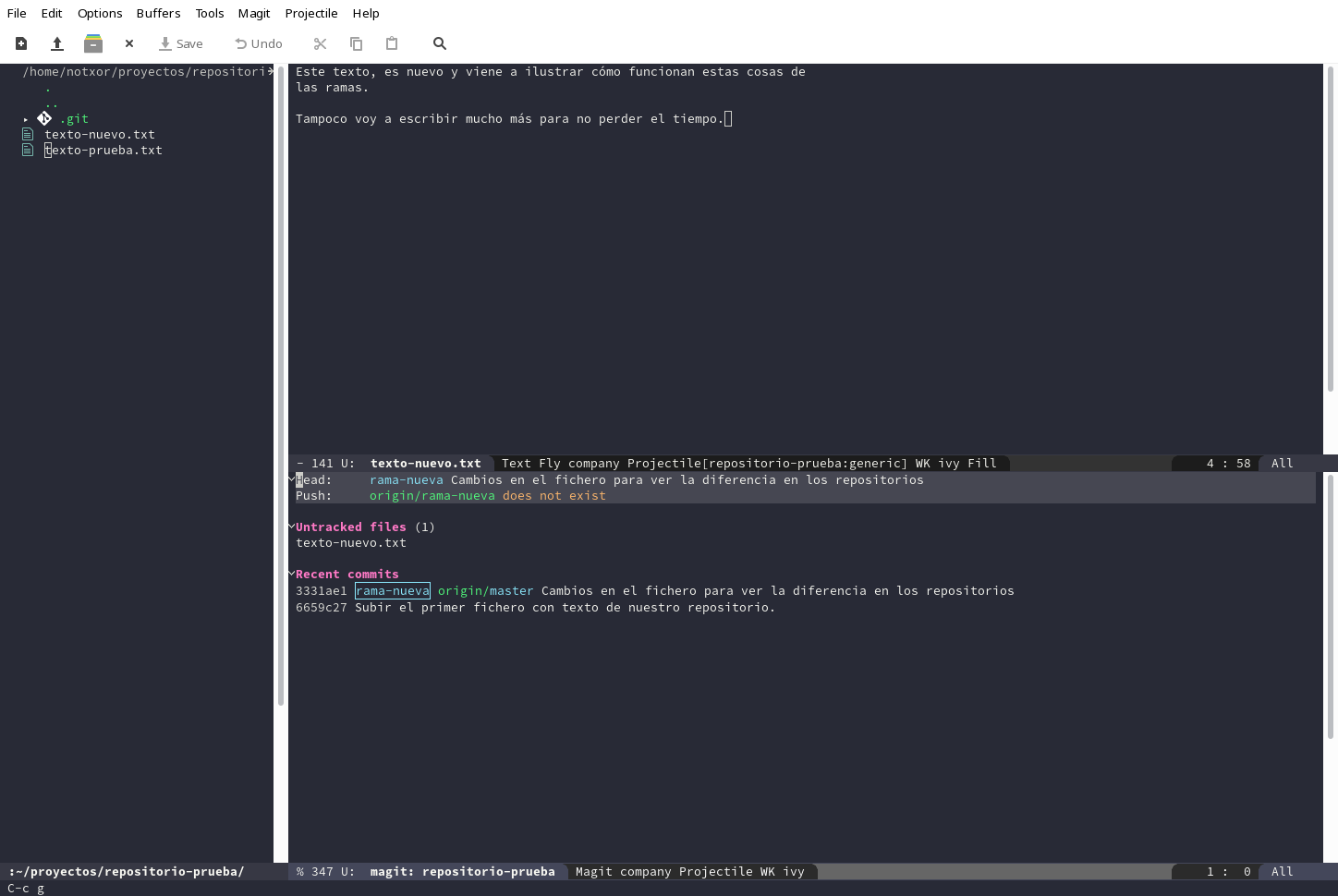
El proceso de stage → commit → push es idéntico al que hemos
hecho para el fichero anterior. La diferencia es que la rama remota no
existe y vamos a crearlo. Al hacer el push seleccionamos u

Nos dirá que la rama remota no existe y que qué rama utiliza para el
push y entre las opciones aparecerá una con la opción con el nombre
origin/nueva-rama
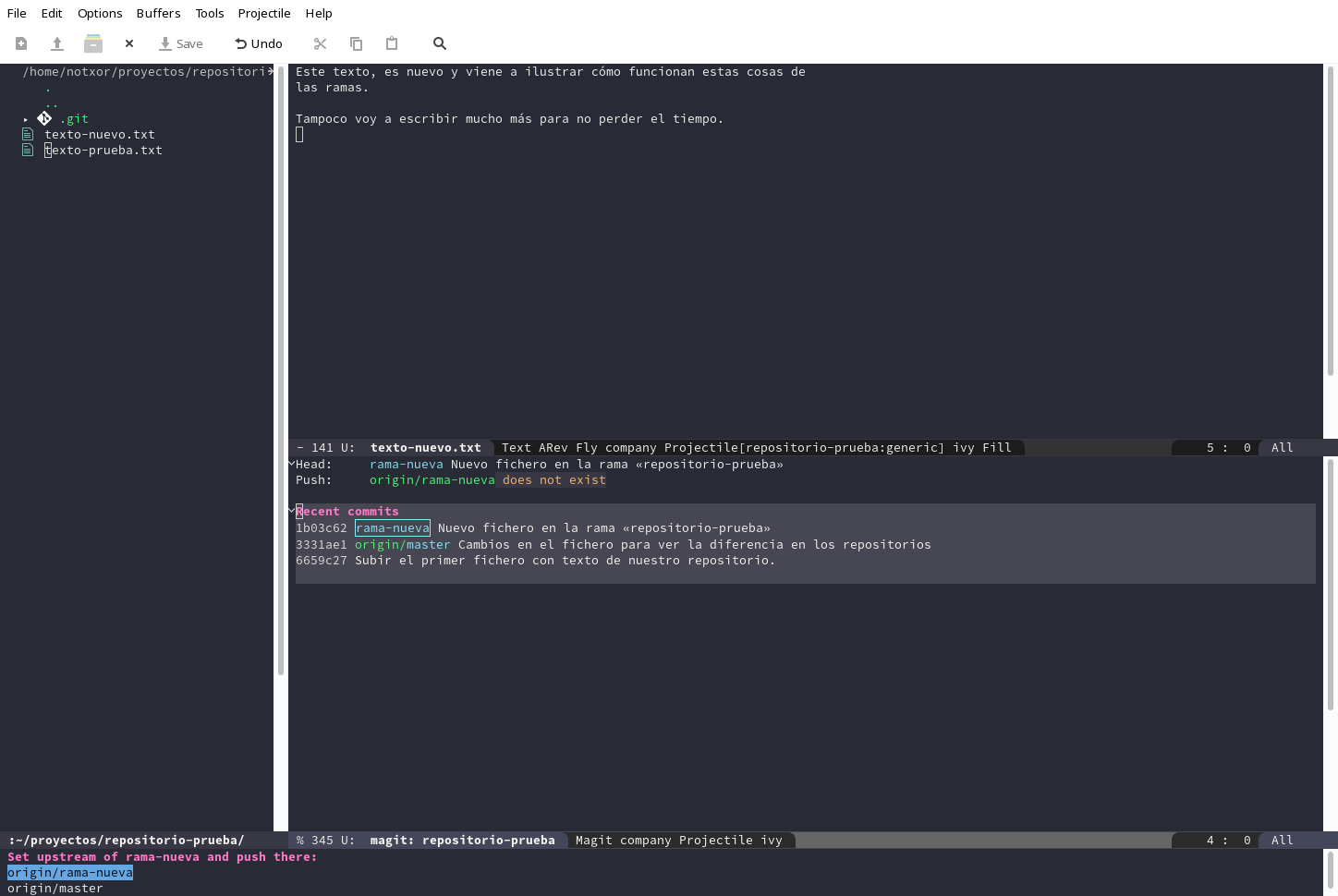
Al seleccionar dicha opción creará una nueva rama en el repositorio
remoto con nuestro contenido. ¿Qué nos dice magit sobre todo esto?
Pues vamos a fijarnos en la siguiente imagen.

Si nos fijamos nuestro HEAD sigue en nueva-rama, un commit más
avanzado que antes. Si miramos los commits recientes veremos que
atrás, ─un commit por debajo─, se queda la rama master, tanto la
local como la remota.
¿Qué ocurre si cambiamos de rama? Pues vamos a verlo: magit-checkout
y nos dejará seleccionar a qué rama queremos mudarnos. En nuestro caso
seleccionaremos master que es una rama local y obtendremos algo como
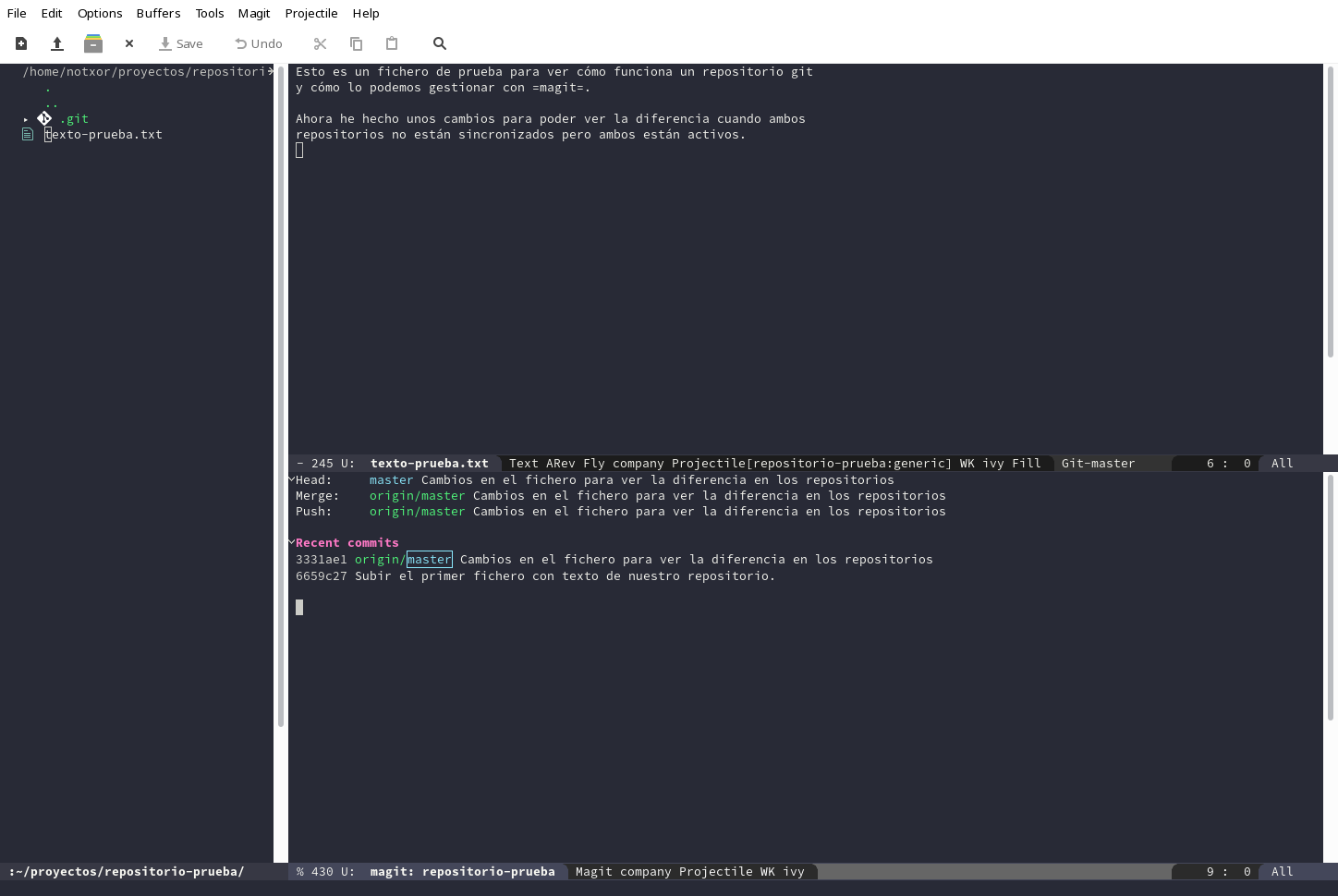
¿Eh? El fichero nuevo que con tanta dedicación he hecho, ¡ha desaparecido! ¡Maldición! ¡Córcholis! ¡Cáspita! (Hmmm, no se me ocurren más tontás que decir, ya si eso otro día sigo con las imprecaciones ñoñas).
Pues eso, han desaparecido todos los cambios que hubiéramos hecho en la rama... NO, simplemente están en la otra rama. Si volvemos a cambiar de rama volverán a aparecer. Ahora mismo tenemos dos versiones independientes, por decirlo de algún modo, de nuestro trabajo.
Fetsh y pull
Pues como suponemos que nuestro repositorio es compartido, es posible
que alguien suba modificaciones al mismo. Ese hecho hará que nuestro
repositorio local esté fuera de sincronía también: ¿cómo volvemos a
sincronizar el repositorio local con el remoto? Pues tenemos dos
opciones fetsh o pull... veamos cómo hacerlo desde magit:
Desde la ventana de
magit, pulsamosf, si queremos hacerfetch, oF, si queremos hacerpull.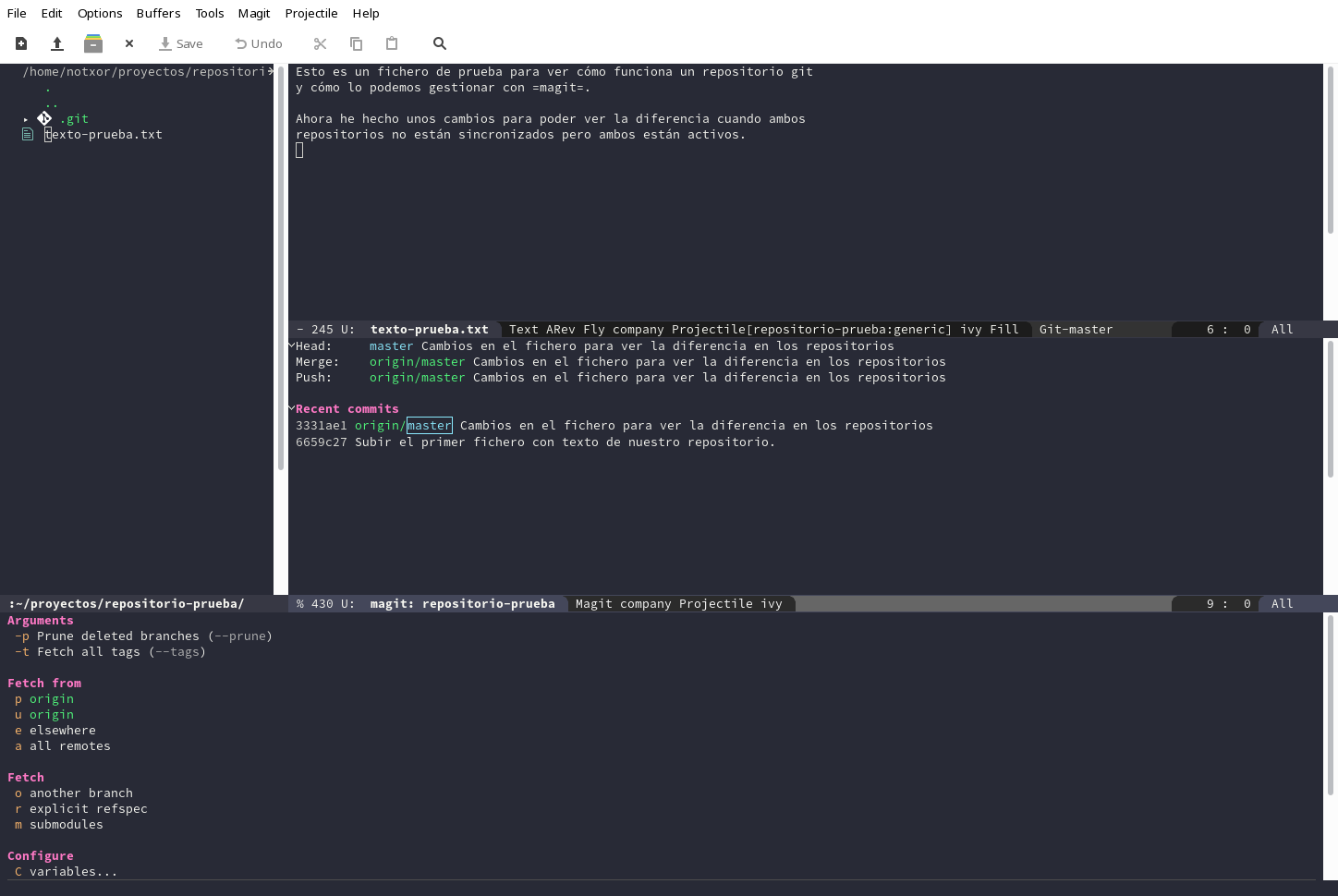
El diálogo que aparece nos permite seleccionar el repositorio, si hubiera más de uno, del que queremos bajar los cambios remotos. Pulsamos
upara que baje los deorigin. Y nuestro repositorio nos informa, de que efectivamente tenemos cambios sin actualizar, véase el apartado deUnpulled from...en la ventana:
Mirando los cambios que han hecho decidimos que son correctos y los importamos a nuestro repositorio con
F, que como he dicho antes, lo que hace es unpull.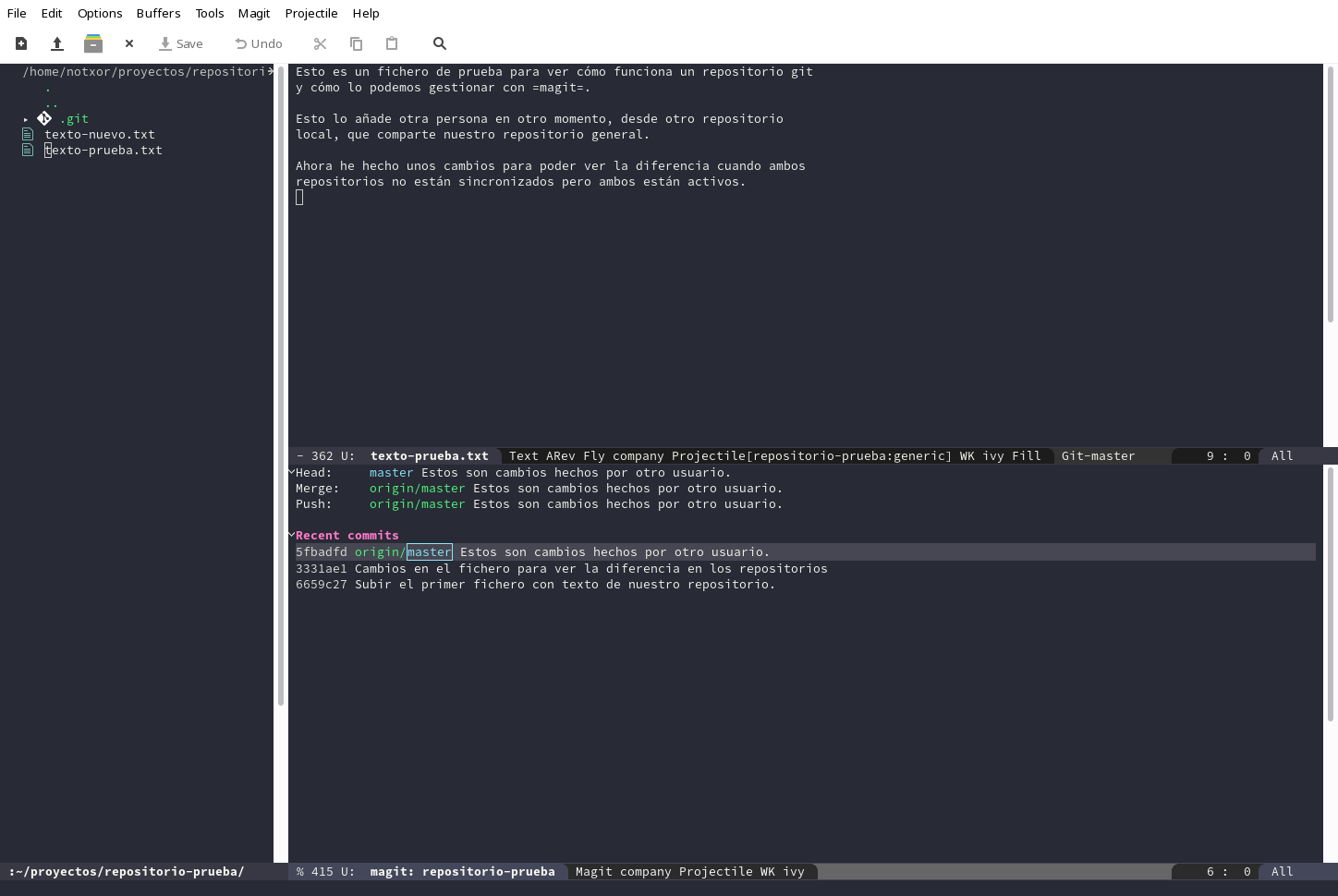
Ya tenemos nuestro repositorio local de nuevo sincronizado con el remoto. Además hemos introducido la imponderable variable del trabajo en equipo y vemos que podemos trabajar en paralelo. Aunque seguro que encontraremos ocasiones en las que nuestros cambios entren en conflicto con los cambios de otros... no nos precipitemos.
Rebase
Al principio entendía rebase como superar o adelantar y el
concepto se me rompía en las entendederas. Al final, me he
acostumbrado a entenderlo como poner base de nuevo o cambiar la
base de la rama (gracias a deesix del IRC, que supo darle el
enfoque al concepto que hizo click en mi cuadriculada mente).
Como hemos visto antes, nuestra rama master ha cambiado y nuestra
rama tiene cosas que no están allí y por otro lado la rama master
tiene cosas que nuestra rama de trabajo local no tiene. ¿Podemos hacer
que esos cambios vengan a mi rama de trabajo para tenerlos en cuenta?
Pues sí, podemos hacerlo con un rebase. Atención: para modificar el
contenido de cualquier rama debemos situarnos en la rama que debe
cambiar. En nuestro caso, la rama rama-nueva va a cambiar su
contenido base, se va a rebasar (volver a basar) en master. Por
tanto, vamos a asegurarnos que estamos en la rama adecuada:
magit-checkout y seleccionamos rama-nueva. Todo debe cambiar a
algo como:

Observa que la rama en la línea de estado del fichero que está abierto
es, efectivamente Git-nueva-rama y además en nuestra ventana de
magit el HEAD apunta a la misma rama. Pues nada, hechas las
comprobaciones necesarias pulsamos r y nos aparece el menú de
opciones del rebase

Seleccionamos e (elsewhere) y después la rama master y...
¡Mierda! ¡Ya han «tocao argo» y falla el rebase! ¿Pero qué ha fallado?
pues pulsamos $ como nos dice el aviso de error y vamos a ver:

Bien, parte del contenido se ha añadido, pero tenemos otra parte que
no en el apartado Unstaged changes del magit. Pulsamos <RET>
sobre dicha cabecera y nos mostrará el conflicto:

Bien vale, ahí está el problema (ya se ve que está hecho a propósito
para que falle... pero hay veces que no y el problema no lo puede
resolver el programa él solo y necesita que lo resolvamos nosotros).
¿Cuál es el texto bueno? Pues en esa ventana de diff volvemos a
pulsar <RET>... esto nos debe llevar al fichero que ha generado el
conflicto.
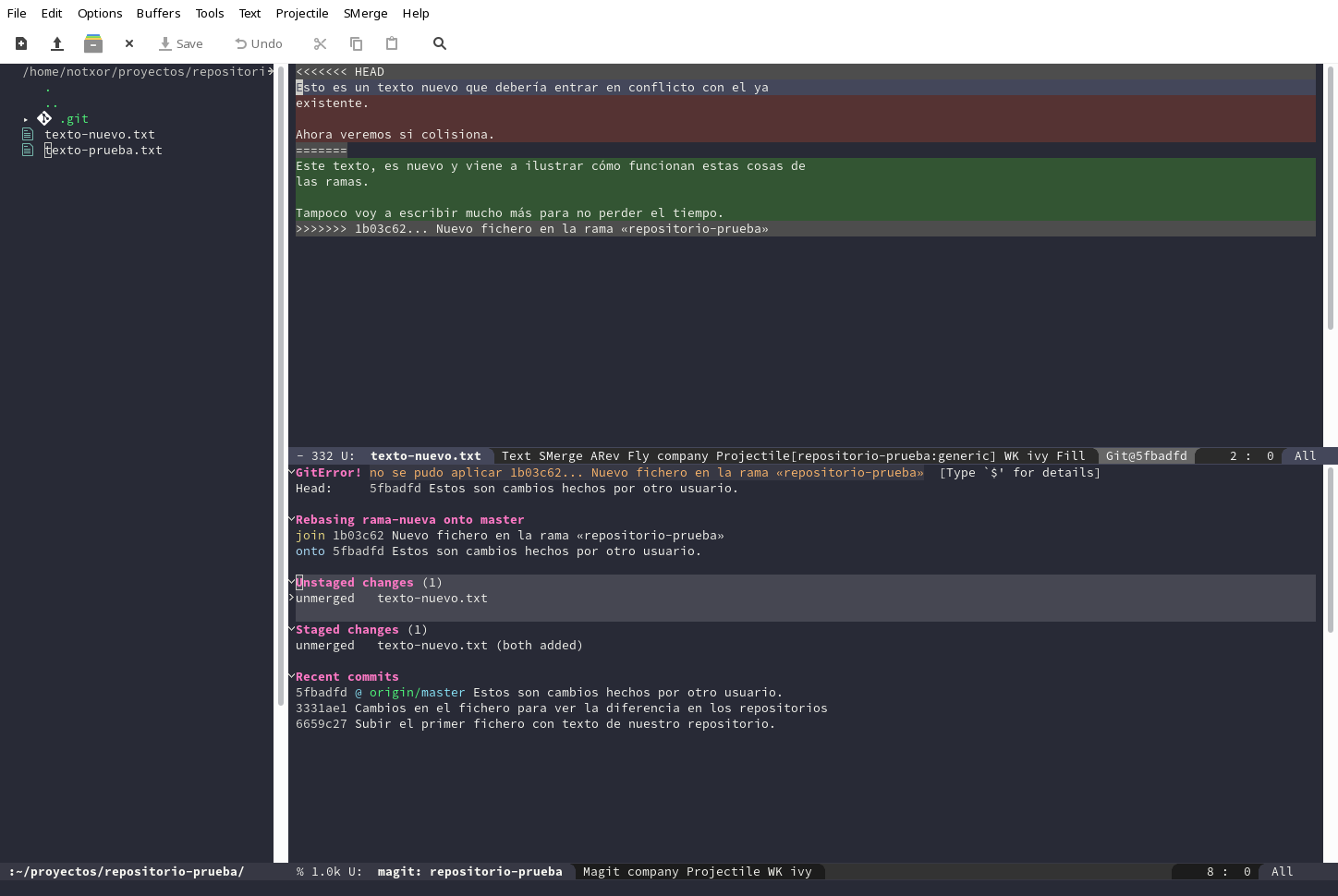
Vemos que Emacs nos remarca las partes que entran en conflicto con
colores, aprovechando que git nos los marca entre las etiquetas
<<<<<<< y >>>>>>> y además separados por la etiqueta =======
<<<<<<< HEAD Esto es un texto nuevo que debería entrar en conflicto con el ya existente. Ahora veremos si colisiona. ======= Este texto, es nuevo y viene a ilustrar cómo funcionan estas cosas de las ramas. Tampoco voy a escribir mucho más para no perder el tiempo. >>>>>>> 1b03c62... Nuevo fichero en la rama «repositorio-prueba»
Cambiamos el texto corrigiendo lo que haga falta. Cuando quitemos esas etiquetas, el texto dejará de marcarse en colores. Para el ejemplo, lo he modificado a algo así:
Esto es un texto nuevo que debería entrar en conflicto con el ya existente. Ahora veremos si colisiona... Efectivamente han colisionado y lo tenemos que arreglar a mano. Este texto, es nuevo y viene a ilustrar cómo funcionan estas cosas de las ramas. Tampoco voy a escribir mucho más para no perder el tiempo.
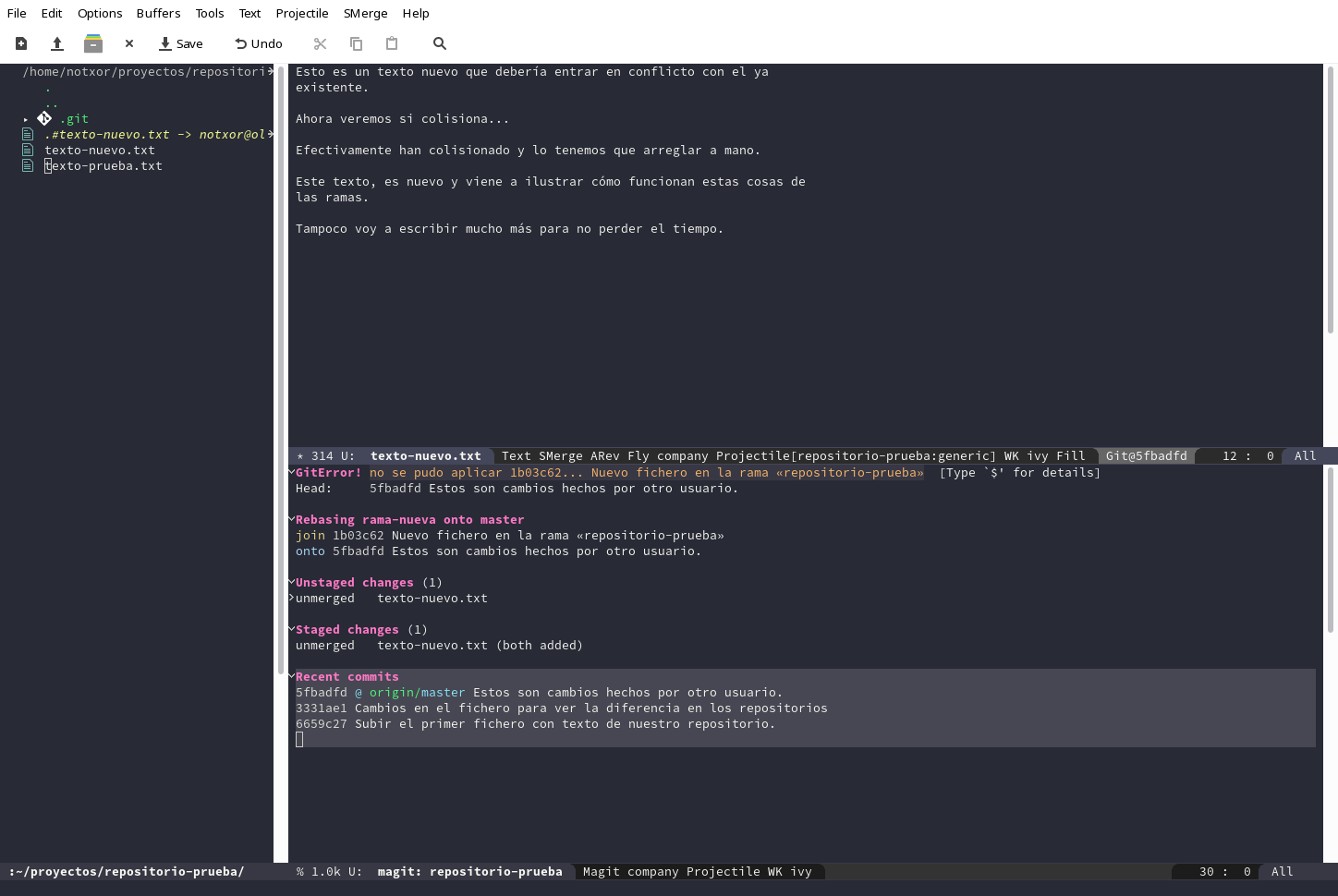
Bien, ya hemos corregido el error ¿y ahora qué? Pues vamos, lo primero
a guardar los cambios y después vamos a la etiqueta Unstaged changes
que mencionamos antes y pulsamos s (stage en inglés) para
indicarle a git que ya hemos resuelto los cambios y lo tenemos todo
listo para continuar nuestro accidentado rebase. ¿Os acordáis de qué
tecla lanzaba el rebase? ¿Sí? efectivamente, pulsamos la misma tecla
r y nos aparece el siguiente menú:

Efectivamente, entre las opciones debemos elegir continuar el rebase
pulsando de nuevo la tecla r y nos pedirá hacer un commit con el
contenido que hemos tenido que arreglar a mano.
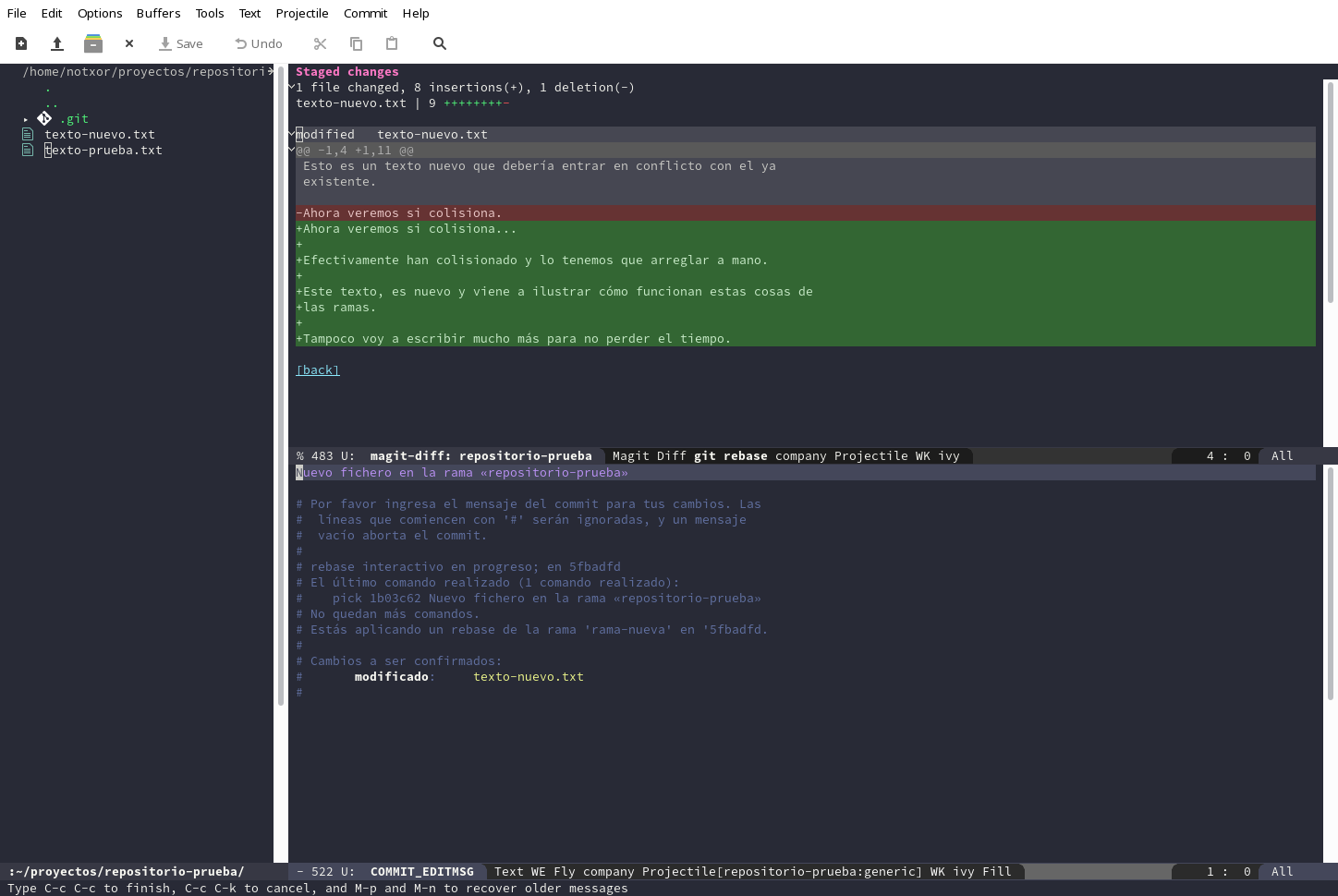
Podemos dejar el mensaje tal cual, pero a mí me gusta avisar que he tenido que resolver los conflictos a mano, también para avisar a quien haya hecho los cambios, que algunas cosas que encuentre en su código o fichero, no coincidirán con lo que escribió.
Merge
Resueltos todos los conflictos que encontremos podemos seguir con
nuestras modificaciones, hacer nuestros commits, y todo el trabajo
como hasta ahora. Pero llega un momento que nuestro trabajo va a
necesitar estar en master... ¿cómo hacemos para llevar nuestra rama
a otra? (en este caso a master). Pues para eso se inventó el merge
que es el proceso por el que los contenidos se mezclan. Igual que
antes con el rebase, vamos a situarnos en la rama que recibe los
cambios, en nuestro caso master... y también tienes que estar
preparado para que aparezcan conflictos (pero como ya sabes que es
relativamente sencillo sobreponerse a ellos, pues adelante sin miedo).
Por pasos:
- Nos situamos en la rama que recibe los cambios:
magit-checkouty seleccionamosmaster. En la ventana de
magit, pulsamosm(merge en inglés).
- En este caso utilizo la combinación
-n, para añadir el equivalente de línea de comandos--no-ffy despuésmpara realizar elmerge. - Nos pregunta qué rama queremos «mergear» y en nuestro caso
seleccionamos
rama-nueva.
Si todo ha ido bien, como es de esperar en el ejemplo, porque los
conflictos venían resueltos de antes y nadie más (es decir, yo
haciendo de mi alter ego el enano cabrón que me jode los commits)
pues hemos acabado el merge.
Si se presentaran conflictos, pues tendríamos que hacer como antes:
arreglar el texto a mano, ir guardando, hacer más commits... lo que
necesitemos para dejar todo listo y suave.
Log
Una forma de tener de un vistazo el repositorio con su historial de
commits es el comando magit-log que como su nombre indica, igual
que todos los comandos que venimos viendo es el equivalente de git
log. ¿Qué ventajas tiene la interface de Emacs? Vamos a ver cómo
está nuestro repositorio pulsando l (log en inglés), en la ventana
de magit. Nos aparecerá el menú para abrir la pantalla de log:
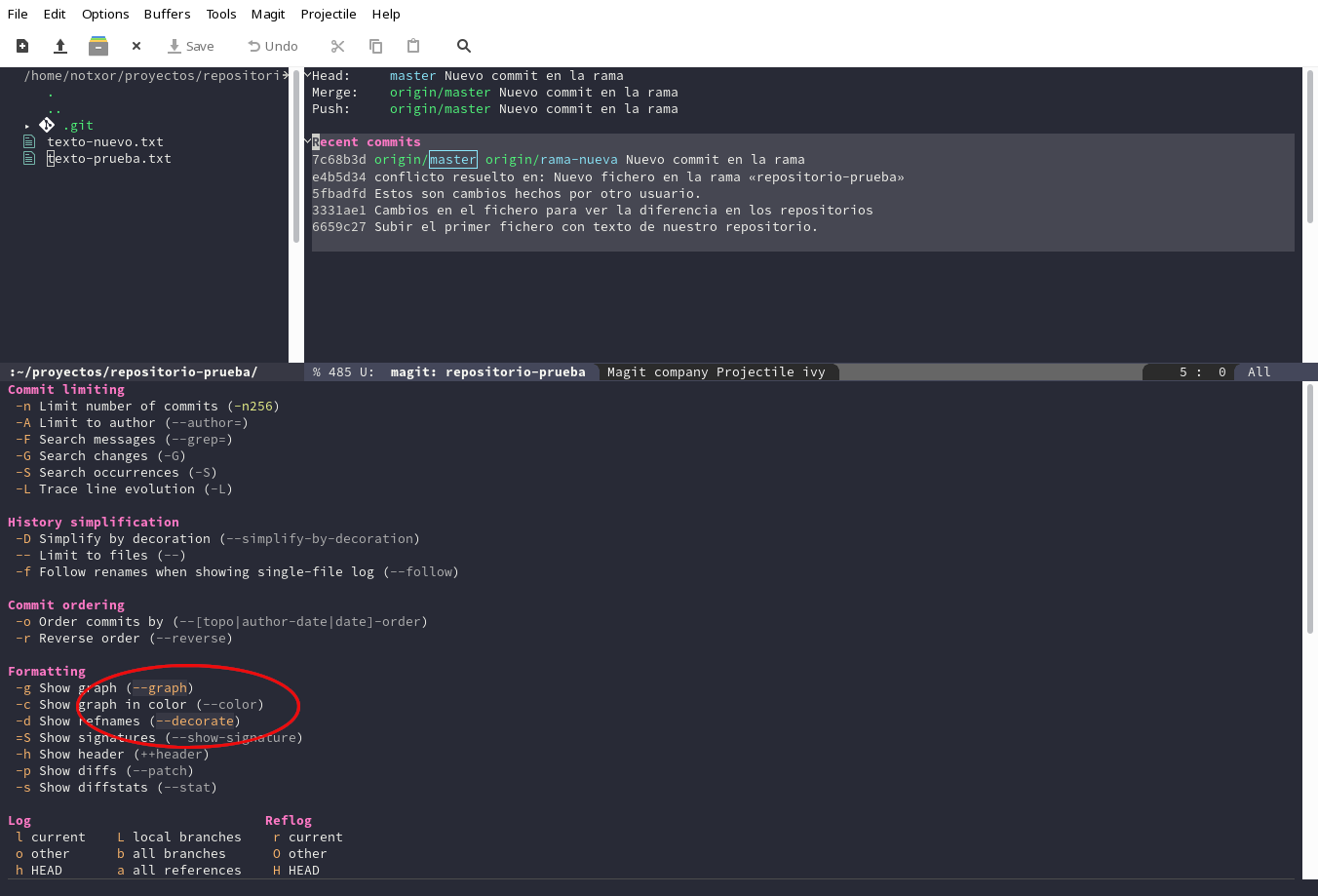
Aprovechando este menú, remarco las opciones que están activadas. Si
pulsamos un - se supone que queremos introducir alguna opción,
limitando la búsqueda u otros parámetros. En nuestro caso, vamos a
pulsar b para que nos muestre todas las ramas y nos aparecerá una
lista con los commits que hemos ido haciendo. Nuestra lista es muy
simple, pero cuando empiezan a aparecer ramas, la cosa se complicará
más.

Pulsando <RET> en cualquiera de la línea nos mostrará los detalles
del commit:
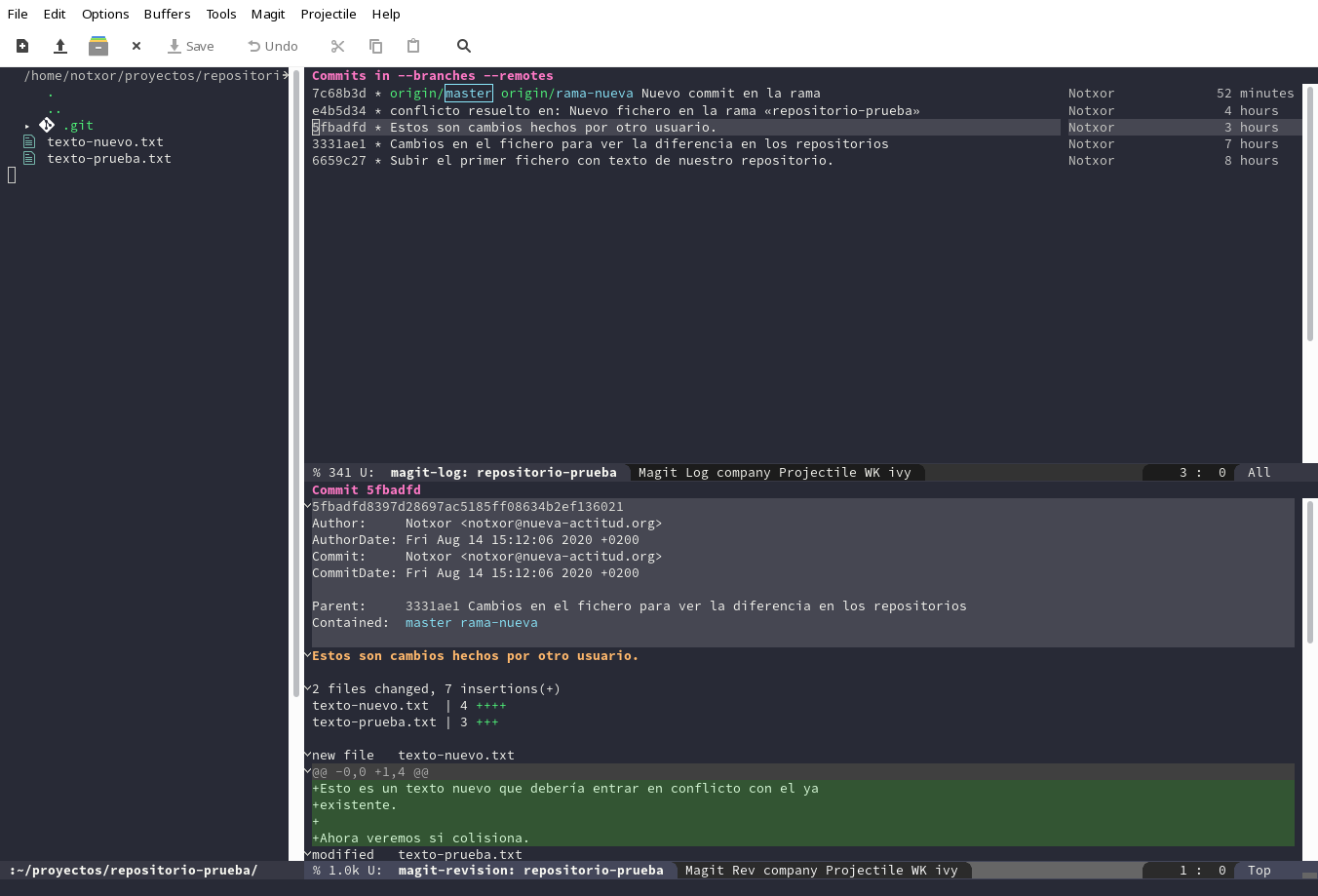
Conclusiones
git es una excelente herramienta y no sólo sirve para gestionar
código. Cualquier cosa, sobre todo si está en texto plano, puede
beneficiarse de las ventajas que esta herramienta nos proporciona.
Puedes hacer modificaciones sin miedo, siempre puedes revertir los
cambios, volver a un commit anterior, abandonar una rama que no da
los resultados esperados, etc.
He explicado apenas unas pocas cosas, sin meterme en complicaciones de
pasar archivos entre ramas o cosas de pro... como hacer los stages
por partes (si eres curioso, tan sólo pulsa <TAB> en los cambios que
esperan ser cargados, muévete a la parte que quieras y pulsa s
(stage) en las líneas que quieras. Verás que el resto sigue marcado
como unstaged). Aún, a pesar de no haber profundizado mucho, este
artículo es uno de los más largos que he escrito en el blog. También
porque está dirigido a personal no-programador que me ha preguntado
por esta herramienta, y creo que la guía visual de los pasos le vendrá
muy bien para manejarse, junto con un poco de git que ya sabe, con
la herramienta de magit de Emacs.
A los programadores que lean esto, les parecerá, quizá, un artículo muy básico, porque hablo de herramientas que quizá ellos utilizan todos los días y a las que están acostumbrados. Siento haberos aburrido.
Y aquí acabo otro de esos artículos suicidas escritos a toda prisa sin que reposen en el estado de borradores. Ya me perdonarán las disculpas.




Comentarios