
Un revuelto de cosas mías
Llevo un tiempo sin escribir y la verdad que no es por falta de ganas, sino porque me enfrasco en mis cosas y no termino de encontrar temas que piense que son interesantes para el resto del mundo mundial. ¿En qué ando enfrascado? y ¿qué me he decidido a contar hoy aquí?. Pues veamos:
- Continuar con el aprendizaje de Lua. En concreto, desarrollar un sistema en el que dicho lenguaje esté embebido en una aplicación En concreto en una aplicación escrita en C..
- Probando
egloten más profundidad para uso personal. - De manera tangencial probando el desempeño de varios lenguajes, subjetivamente.
Lua y C
Para aprender el lenguaje y sus interacciones, estando embebido en una aplicación escrita en otro lenguaje, necesitaba una aplicación que hospedara un intérprete de Lua para hacer funcionar algo. Debía ser una aplicación suficientemente compleja como para poner a prueba el asunto, pero que no me distrajera del objetivo último, que es aprender Lua y sus idiosincrasias.
Elegí un proyecto con el que estoy ya familiarizado, un raytracer. El objetivo es hacer una aplicaciónEn C. que genere una imagen que venga descrita en un script escrito en Lua.
El primer paso consistió en programar en Lua el mismo raytracer que se desarrollará en C hasta alcanzar un punto en que hubiera más de un objeto (en concreto dos esferas) y una abstracción de cámara para hacer la imagen. Además, también con el objeto de aprender, implementé un sistema de corrutinas que remedaban un proceso paralelo. En realidad, Lua no implementa ese paralelismo, por mucho que llame thread al proceso que realiza una corrutina, no es un hilo independiente. Me sirvió para aprender cómo gestionarlas y si lo necesitara más adelante, bastaría con lanzar la corrutina en un nuevo intérprete.
Llegados a este punto, me puse a desarrollar lo mismo en C. La primera impresión fue el cambio en velocidad. No quiere decir que Lua sea lento, sino que C es rapidísimo. Por poner un sencillo ejemplo:
El código en Lua:
local math = require("math") local string = require("string") local function main() -- Imagen local ancho_imagen = 256 local alto_imagen = 256 -- Render print("P3\n" .. ancho_imagen .. " " .. alto_imagen .. "\n255\n") for j = 1, ancho_imagen do io.stderr:write(".") -- muestra un punto por cada línea dibujada for i = 1, alto_imagen do local r = i / ancho_imagen local g = j / alto_imagen local b = 0.0 local er = math.modf(255.99999 * r) local eg = math.modf(255.99999 * g) local eb = math.modf(255.99999 * b) print(string.format("%d %d %d", er, eg, eb)) end end io.stderr:write(" Hecho.\n") end main()
Ejecución y desempeño:
time lua .ejemplo.lua > ejemplo_lua.ppm
________________________________________________________ Executed in 331.23 millis fish external usr time 69.97 millis 0.00 millis 69.97 millis sys time 260.53 millis 1.64 millis 258.89 millis
Si comparamos este código con el equivalente de C:
#include <stdio.h> int main() { int ancho_imagen = 256; int alto_imagen = 256; printf("P3 %d %d 255\n", ancho_imagen, alto_imagen); for (int j = 0; j <= alto_imagen - 1; j++) { fprintf(stderr, "."); for (int i = 0; i <= ancho_imagen - 1; i++) { double r = (double) i / ((double) ancho_imagen - 1); double g = (double) j / ((double) alto_imagen - 1); double b = 0.0; int ir = (int) 255.9999 * r; int ig = (int) 255.9999 * g; int ib = (int) 255.9999 * b; printf("%d %d %d\n", ir, ig, ib); } } fprintf(stderr, "-> Hecho.\n"); }
Compilado, ejecución y desempeño:
gcc -o ejemplo_c ejemplo.c
time ./ejemplo_c > ejemplo_c.ppm
________________________________________________________ Executed in 15.85 millis fish external usr time 10.19 millis 0.00 millis 10.19 millis sys time 4.53 millis 1.48 millis 3.06 millis
Comparaciones odiosas
Sí, soy consciente de que no son comparables, uno es un lenguaje interpretado y otro un lenguaje compilado... para ser más odioso aún, implementé el mismo ejemplo en Rust con el siguiente resultado:
________________________________________________________ Executed in 277.37 millis fish external usr time 17.41 millis 1.41 millis 15.99 millis sys time 260.06 millis 0.16 millis 259.90 millis
O dicho de otro modo:
| Lenguaje | usr |
sys |
total |
|---|---|---|---|
| Lua | 69.97 | 260.53 | 331.23 |
| C | 10.19 | 4.53 | 15.85 |
| Rust | 17.41 | 260.06 | 260.06 |
Es decir, Rust se acerca más a C en el tiempo dedicado en usr pero
gasta el mismo tiempo que Lua en sys. Será también mucho más rápido
que Lua en un proceso de cálculo más largo y exigente, pero en este
ejemplo corto, apenas consigue ventaja.
No le daré más vueltas de momento a estos temas, que dejaré para más adelante, porque puestos a mirar el asunto, añadí algún lenguaje compilado más, como nim y zig.
El proyecto de aprendizaje aún está en desarrollo y me estoy divirtiendo un montón con él. Si consigo una buena integración entre ambos lenguajes no me extrañaría que lo siguiera desarrollando un poco, para conseguir mayor complejidad. Me refiero a verdadera multitarea, más tipos de objetos que simples esferas, otros formatos de salida (PNG, JPEG...) y, en fin, un raytracer más completo.
Usando Emacs para programar
Como he dicho antes estoy en fase de pruebas más profundas de eglot
aprovechando este proyecto. Lo tengo activado tanto en Lua como C. Si
tienes curiosidad por conocer qué configuración estoy usando, el
código está en su repositorio: https://codeberg.org/Notxor/init-emacs.
En el caso del lenguaje C estoy probando las dos herramientas LSP que
tengo disponibles: clangd y ccls. Ambos cuentan con paquetes propios
para OpenSuse Tumbleweed y se instalan sin problemas. El primero viene
integrado en los paquetes de desarrollo de clang y LLVM, y el segundo
viene en un paquete aparte.
El desempeño de ambos es correcto, con sus puntos fuertes y débiles.
Por ejemplo, la información que ofrece clangd me está pareciendo más
completa, pero a cambio de tocar un poco más las gónadas con cosas que
aparecen (y desaparecen) según le parece a él durante la edición. De
vez en cuando, con el ánimo de probar ambos, cambio entre ellos y como
resumen puedo decir que me gusta más ccls por su sencillez y por no
molestarme con demasiados desplegables o introduciendo elementos
visuales entre el código. Una costumbre que sí tiene clangd, que
inserta visualmente en las llamadas a una función el nombre de los
parámetros que se encuentran en su definición... es información
relevante, pero me resulta incómodo leer el código así.
Depurando el código con gdb
Durante la programación me he encontrado con algunos errores para los
que he necesitado utilizar un depurador. Recuerdo que años atrás,
antes de descubrir las capacidades de Emacs, utilizaba herramientas
como ddd para depurar. En la actualidad me encuentro más cómodo con el
depurador integrado en Emacs.
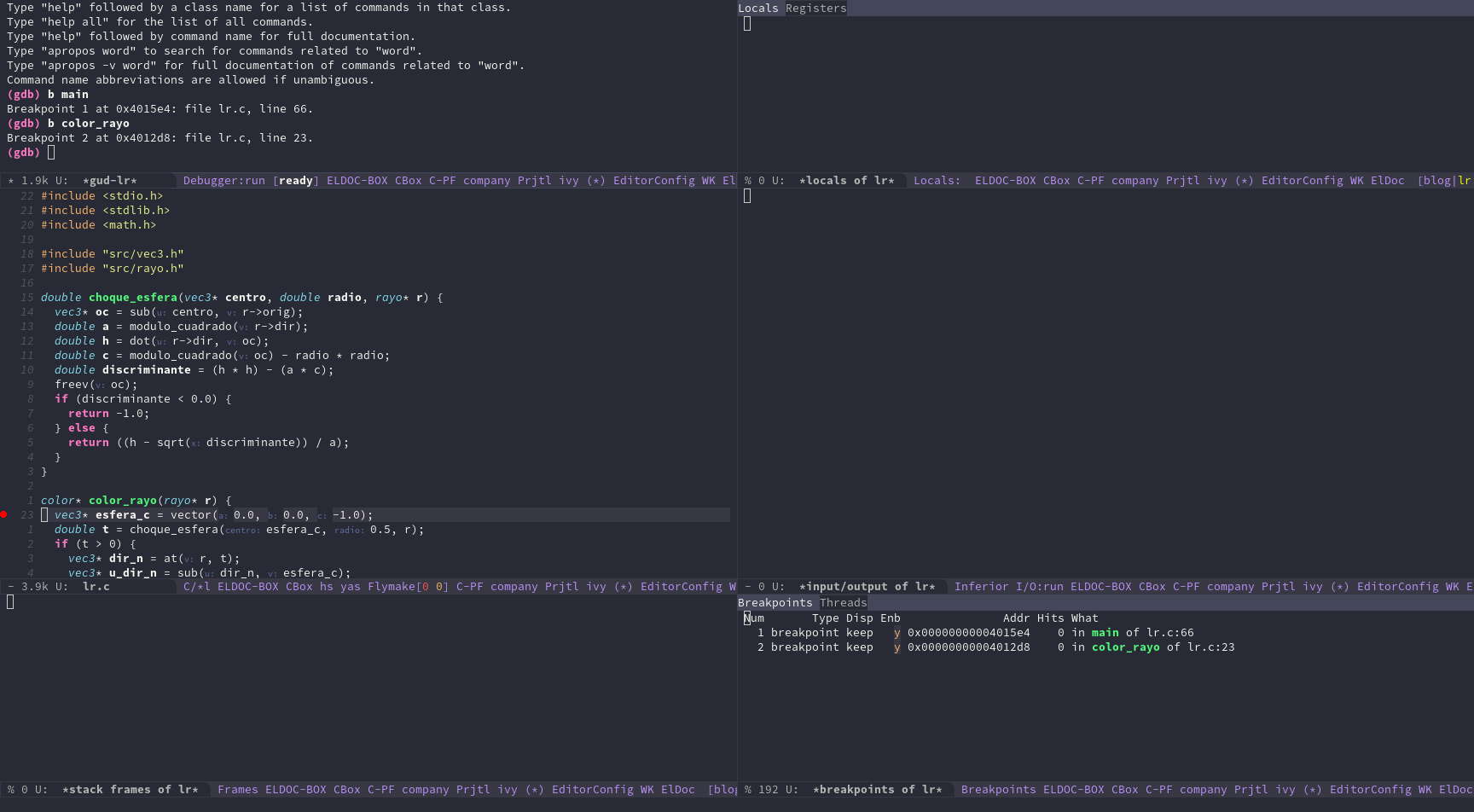
Esta ventana aparece cuando lanzamos projectile-run-gdb si tenemos
activado gdb-many-windows. Vemos seis ventanas:
gud |
VV locales |
| código | Entrada-Salida |
| pila llamadas | Breakpoints |
La ventana superior izquierda nos permite interactuar con gdb. Si no
lo has utilizado frecuentemente los comandos más habituales son:
gdb |
gud |
Acción |
|---|---|---|
b |
C-x C-a C-b |
Establece un breakpoint. |
d N |
C-x C-a C-d |
Elimina el breakpoint N. |
r |
C-x C-a C-v |
Ejecuta el programa hasta encontrar un breakpoint o un error. |
c |
C-x C-a C-r |
Continúa la ejecución hasta encontrar el siguiente breakpoint o un error. |
f |
Ejecuta el programa hasta finalizar la función en curso. | |
s |
C-x C-a C-s |
Ejecuta la siguiente línea de código. |
s N |
Ejecuta las siguientes N líneas. | |
n |
C-x C-a C-n |
Como s pero sin entrar en las funciones llamadas. |
u N |
C-x C-a C-u |
Ejecuta el código hasta que se encuentra a N líneas de la actual. |
p var |
C-x C-a C-p |
Muestra el valor de la variable var. |
u |
C-x C-a < |
Sube un nivel en la pila de ejecución. |
d |
C-x C-a > |
Desciende un nivel en la pila de ejecución. |
q |
Sale del depurador. |
Se puede utilizar tanto el comando de gdb como el de gud.
A pesar de estar en las primeras fases del proyecto, me he visto ya en la necesidad de utilizarlo y es una de esas joyas de las que no se suele hablar. Según vas ejecutando puedes ir viendo cómo cambia la pila de llamadas, las variables locales y demás información.
Por ejemplo, al principio no me preocupaba la gestión de memoria. Apenas abría unas cuantas variables y no me producía ningún problema que se quedaran activos algunos punteros hasta que terminara la ejecución del programa y el S.O. liberara los recursos reservados por el programa. Para ser sincero, tampoco me crea muchos problemas de memoria en su estado actual, sin embargo, el uso de la memoria ha crecido exponencialmente. Todo el raytracer está basado en vectores 3D, incluso los colores son vectores de tres posiciones. Y cada posición es un double, por lo que un vector, un punto del espacio o un color, consumen 24 bytes. Por otro lado, un rayo está formado por un punto y un vector de dirección, por lo que consume 48 bytes. Por cada pixel de una imagen hay que lanzar al menos un rayo. Con el antialising, esto se multiplica, que pueden ser 100 rayos por pixel... con unos sencillos cálculos te darás cuenta que además de los 24bytes del color del pixel, necesitas 4.8Kb para calcularlo. Aún siendo una imagen pequeña, gastar 4.824 bytes en cada pixel, es un gasto considerable. Por ejemplo, una prueba de 400x225 pixeles son 434.160.000 bytes que son 414Mb. La solución es liberar cada rayo, cada punto, cada vector cuando deja de ser necesario.
Pruebas con distintos lenguajes
Como ya apunté antes, cuando me puse a trabajar con C, me encontré haciendo pruebas con distintos lenguajes Lua, C, Rust... y añadí también otro par de los lenguajes compilados: nim y Zig. ¿Para qué? Pues para probar, simplemente. Soy consciente de que estas pruebas no están optimizadas, es un bucle pequeño, por lo que no esperaba encontrar muchas diferencias entre ellos. Para comenzar, colocaré aquí el código.
Rust:
fn main() {
// imagen
let ancho_imagen: i32 = 256;
let alto_imagen: i32 = 256;
println!("P3 {} {} 255", ancho_imagen, alto_imagen);
for j in 0..alto_imagen {
eprint!(".");
for i in 0..ancho_imagen {
let r: f64 = (i as f64) / ((ancho_imagen as f64) - 1.0);
let g: f64 = (j as f64) / ((alto_imagen as f64) - 1.0);
let b: f64 = 0.0;
let ir: i32 = (255.9999 * r) as i32;
let ig: i32 = (255.9999 * g) as i32;
let ib: i32 = b as i32;
println!("{} {} {}", ir, ig, ib);
}
}
eprintln!("->Hecho.");
}
Compilación con el comando:
rustc -o ejemplo_rust -O ejemplo.rs
Nim:
proc main():void =
var ancho_imagen: int = 256
var alto_imagen: int = 256
echo "P3 ", ancho_imagen, " ", alto_imagen, " 255"
for j in 0..alto_imagen-1:
for i in 0..ancho_imagen-1:
var r: float = float(i) / (float(ancho_imagen) - 1)
var g: float = float(j) / (float(alto_imagen) - 1)
var b: float = 0.0
var ir: int = int(255.9999 * r)
var ig: int = int(255.9999 * g)
var ib: int = int(255.9999 * b)
echo ir, " ", ig, " ", ib
main()
Compilación:
nim c --opt:speed ejemplo.nim
Zig:
const std = @import("std");
pub fn main() !void {
const stdout = std.io.getStdOut().writer();
const ancho_imagen: i32 = 256;
const alto_imagen: i32 = 256;
try stdout.print("P3 {} {} 255\n", .{ ancho_imagen, alto_imagen });
for (0..alto_imagen) |j| {
for (0..ancho_imagen) |i| {
const r: f64 = @as(f64, @floatFromInt(i)) / (ancho_imagen - 1);
const g: f64 = @as(f64, @floatFromInt(j)) / (alto_imagen - 1);
const b: f64 = 0.0;
const ir: i32 = @as(i32, @intFromFloat(255.9999 * r));
const ig: i32 = @as(i32, @intFromFloat(255.9999 * g));
const ib: i32 = @as(i32, @intFromFloat(255.9999 * b));
try stdout.print("{} {} {}\n", .{ ir, ig, ib });
}
}
}
Compilación:
zig build-exe ejemplo.zig
Los resultado son los siguientes:
| Lenguaje | usr |
sys |
total |
|---|---|---|---|
| C | 10.19 | 4.53 | 15.85 |
| Rust | 17.41 | 260.06 | 260.06 |
| nim | 39.48 | 523.69 | 563.03 |
| Zig | 160.00 | 2980.00 | 3140.00 |
No son pruebas definitivas. Es decir, llama la atención que un lenguaje compilado, como Zig se vaya a los 3,14 segundos en la ejecución obteniendo peores resultados incluso que Lua.
Seguramente, cualquier lenguaje de esos puede compilarse más optimizado y por desconocimiento no lo hice.
Conclusiones
La principal es que ando con mis cosas. No me olvido del blog, pero cada vez me cuesta más encontrar temas interesantes. Para mí era más fácil escribir cuando escribía sólo para mí. Desde que me di cuenta que había gente que lo leía pienso más en qué puede interesar a otros que en lo que me interesa a mí. Pero normalmente ando haciendo algún proyecto personal, que me parece interesante pero que no termino decidirme a contarlo por aquí.
Otro tema tangencial son los lenguajes. Para hacer los ejemplos he tenido que hacer uno en Zig, un lenguaje por completo desconocido. Es el primer código que escribo en él. Me ha llamado la atención lo complejo que puede ser su compilador. Parece un lenguaje bastante expresivo y no descarto aprender más sobre él en el futuro.
De momento estoy disfrutando bastante con el raytracer en C y Lua, es posible que lo alargue en sus capacidades.




Comentarios