
Edición y exportación desde org-mode a html
Hay veces que tengo que consultar mi propio blog para recordar cómo
hacer algo y en este artículome niego a llamarlo post. Estoy desanglificando mi forma de hablar —y escribir—.
voy a contar una de esas veces. La historia no es de ahora, llevo
algunos meses pensando en dedicar un poco de mi tiempo a editar libros
para poder leerlos tranquilamente con mi lector. Generar epubs de
calidad es bastante complejo, sobre todo porque no todos los lectores
cargan los archivos igual y el html+css que utilizan está, en
algunos casos, muy limitado.
Ya hice en su día una edición de «La mastro de l' ringoj»1 en
epub. Se lee bien en las aplicaciones de lectura de la tablet, se
leía bien en mi antiguo lector, pero éste se estropeó y al cargar el
libro en uno viejo que ya no utilizábamos y andaba dando vueltas por
casa, pues me di cuenta de cuántos errores de edición había
cometido. No sólo de edición, sino de corrección, ortografía y un
montón de detalles.
Tenía aún los archivos pdf de los que partí y me decidí a hacer una
buena edición. Por tanto, parto de la misma base y, esta vez, espero
hacer un mejor trabajo, poniendo más atención a los detalles. Pero
primero veamos qué inconvenientes me voy a encontrar:
- Los archivos
pdfde los que parto están compuestos de imágenes escaneadas directamente desde el libro físico, página a página. Es decir, cada página del archivo es la imagen de una página escaneada del libro físico. - Las fuentes que más se ajustan a este proyecto —sobre todo las más vistosas para emplearlas en títulos y funciones decorativas—, no soportan las «ĉapelitaj literoj» del Esperanto.
- Sigil, el programa de edición de archivos
epubviene sin diccionario para Esperanto.
Menciono esos tres, pero seguro que me voy a encontrar más. Al menos,
estos tres los tengo identificados y puedo hacer algo al respecto.
Para empezar, en lugar de lanzarme directamente con la edición del
epub, esta vez, voy a hacer un paso intermedio. Voy a generar el
contenido en un remedo de libro web, que me permita navegarlo y
comprobar errores. Para todo el proyecto utilizaré Emacs y
org-mode.
Publicar html desde org-mode
Hace algunos meses ya comenté cómo, pero hacía tanto tiempo que no lo utilizaba que tuve que repasármelo antes de acometer este proyecto. Como ya lo conté en otro artículo no voy a extenderme mucho en cómo hacerlo y me centraré en qué hago.
Estructura de directorios
. ├── du-turegoj │ └── ( ... ) Equivalente a kunularo ├── kunularo │ ├── html │ │ └── ( ... ) Directorio espejo del org pero con los archivos html │ ├── kunularo.el │ └── org │ ├── antauparolo-dua.org │ ├── chapitro01.org │ ├── ( ... ) │ ├── compartido │ │ ├── css │ │ │ ├── estilos.css │ │ │ ├── style.css │ │ │ └── style-rust.css │ │ ├── fonts │ │ │ ├── AngerthasMoria.ttf │ │ │ ├── P052_Roman.ttf │ │ │ ├── RingbearerMedium.ttf │ │ │ ├── TengwarAnnatar.ttf │ │ │ └── Hobbitonbrush.ttf │ │ └── imagenes │ │ ├── firma-metal.svg │ │ ├── firma-negro.svg │ │ ├── firma.svg │ │ ├── kunularo-ringo.svg │ │ ├── mapo-mez-tero.svg │ │ ├── mastro-ringoj.svg │ │ ├── portada-kunularo.svg │ │ ├── provinca-mapo.svg │ │ ├── provinca-mapo-vektoro.svg │ │ ├── runoj_2.svg │ │ └── runoj.svg │ ├── ( ... ) Más archivos .org │ └── unua-libro.org ├── plantilla.org ├── plantillas │ ├── du-turegoj.org │ ├── kunularo.org │ └── reveno-rego.org ├── procesar-ocr.el ├── reveno-rego │ └── ( ... ) Equivalente a kunularo ├── Tolkien-la-du-turegoj.pdf ├── Tolkien-la-kunularo-de-la-ringoj.pdf └── Tolkien-la-reveno-de-la-regxo.pdf
Es una estructura un poco compleja, dado que hay tres libros y voy a hacerlos uno a uno, empezando por el primero La kunularo de l' Ringo2.
Otro de los inconvenientes que me encontré es la poca calidad que en la edición original se puso en las imágenes. Mi solución es vectorizarlo todo y rehacer, dentro de mis posibilidades. Por ejemplo, el mapa de «La Provinco» tiene unos píxeles del tamaño de una piscina olímpica.

Mi solución es vectorizarlo en una imagen svg:

Además de las imágenes, he vectorizado otros elementos y me permite
montar algunas páginas de referencia, como la de «La Unua
Libro»3. El texto completo del archivo unua-libro.org es el
siguiente:
#+setupfile: ../../plantillas/kunularo.org #+include: ./indice.org #+attr_html: :class nav | ← | → | ./compartido/imagenes/runoj.svg #+attr_html: :class sello ./compartido/imagenes/firma-negro.svg #+attr_html: :class pag-tit-libro La Unua Libro ./compartido/imagenes/runoj_2.svg #+attr_html: :class nav | ← | → |
La visualización de dicho archivo es esta:

Si empezamos por el principio, lo primero que hace este archivo es
establecer como setupfile el kunularo.org, que es una plantilla
que configura todos los archivos que componen el primero de los libros
que estoy editando. Su contenido es bastante sencillo, pero lo
explico en el siguiente apartado de setupfile.
La segunda línea lo que hace es importar un archivo que contiene el índice o tabla de contenidos del libro. No se ha puesto en la plantilla, porque no todas las páginas lo importarán y, por tanto, sólo debe hacerse en aquellas páginas que sí necesiten el índice a la izquierda.
Lo siguiente que aparece es un bloque que facilita la navegación del
libro hacia adelante y hacia atrás añadiendo una tabla con los
caracteres ← y → para mostrar el archivo precedente o posterior al
actual. La macro #+attr_html: :class nav lo que hace es añadir al
elemento una propiedad o atributo html que es class="nav" dentro
de la etiqueta <table>. Esa clase está definida en un archivo css
que importa el setupfile. ¡Pero vamos a ver qué hace este archivo!
setupfile
kunularo.org, es una plantilla que configura todos los archivos que
componen el primero de los libros que estoy editando. Su contenido es
bastante sencillo, pero aún así tendrás que soportar que lo explique:
#+author: J. R. R. Tolkien #+title: La kunularo de l' ringo #+date: <2023-06-08> #+options: ':t *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline author:t c:nil #+options: creator:comment d:(not LOGBOOK) date:t e:t email:nil f:t inline:t #+options: num:nil p:nil pri:nil stat:t tags:t tasks:t tex:t timestamp:t toc:nil #+options: html-style:nil html-postamble:auto html-postamble:t #+macro: letra @@html:<span class="$1">$2</span>@@ #+language: eo #+exclude_tags: noexport #+select_tags: export #+html_container: div #+html_doctype: xhtml-strict #+html_head: <link rel="stylesheet" type="text/css" href="compartido/css/style.css" /> #+html_head: <link rel="stylesheet" type="text/css" href="compartido/css/style-rust.css" /> #+html_head: <link rel="stylesheet" type="text/css" href="compartido/css/estilos.css" />
De este archivo, las primeras líneas son evidentes, son el autor, el
título y la fechas, creo que se entienden perfectamente. Más
complejas y, quizá, más difíciles de entender para quien llega nuevo a
org-mode, son las líneas de #+options:. Para explicarlas un poco
quizá venga bien repasar algún artículo donde lo cuento más
detenidamente. Como añadido está la opción html-style:nil, que lo
que hace es evitar que org-mode añada en la cabecera
(<head>...</head>) una etiqueta style, porque al final del
archivo, vamos a importar los estilos que necesita en forma de
archivos css.
Quizá sea más curiosa o digna de explicar la línea de #+macro:. En
este blog también podéis encontrar de manera más detallada cómo se
manejan las macros en org-mode. Pero para que no andes saltando a
otros artículos, si no quieres, una macro lo que hace es generar
texto que se exportará directamente del org al html. En este
ejemplo, el texto:
(...) antaŭpordo de Bilbo la maljunulo komencis malŝarĝi: troviĝis grandaj faskoj da artfajraĵoj ĉiuspecaj kaj ĉiuformaj, unuope etikeditaj per granda ruĝa {{{letra(tengwar,x)}}} kaj la elf-runo {{{letra(runas,G)}}}.
Se convierte en el html:
<p> (...) antaŭpordo de Bilbo la maljunulo komencis malŝarĝi: troviĝis grandaj faskoj da artfajraĵoj ĉiuspecaj kaj ĉiuformaj, unuope etikeditaj per granda ruĝa <span class="tengwar">x</span> kaj la elf-runo <span class="runas">G</span> . </p>
En los css están incluidas las clases tengwar y runas, que
importan las fuentes necesarias y las formatean, para que se muestren
como letras incrustadas.

Las siguientes líneas sobre las tags me permiten mantener texto,
como comentarios o simplemente partes que aún necesitan revisión, que
no quiero que se exporten a la página html.
Lo último son las líneas que añadirán a nuestras cabeceras los enlaces
a los archivos de estilos. Los archivos style.css y style-rust.css
los he obtenido del siguiente repositorio:
https://github.com/ppalazon/org-mode-html-styles/ distribuidos con
licencia Apache 2.0. El último, llamado estilos.css es propio del
proyecto y en él voy añadiendo las entradas para generar los estilos
que necesito.
Procesar los pdf de imágenes
Convertir una imagen de una página a texto es algo, en teoría, sencillo si tienes las herramientas:
- Un programa que extraiga la imagen del
pdf. - Un programa que convierta la imagen en texto mediante
OCR.
Extraer imágenes del archivo pdf
El primer paso consiste en convertir la página correspondiente del
pdf en un archivo de imagen. El programa que utilizo desde la línea
de comandos es pdfimages. Explico cómo funciona con un ejemplo:
pdfimages -png -f 12 -l 27 fichero.pdf pagina
Veamos las opciones de pdfimages:
-png- Especifica que la salida será en formato
png. -f 12- la primera (first) página, será la
12. -l 27- la última (last) página, será la
27. fichero.pdf- será el archivo del que se extraigan las imágenes.
pagina- es la raíz para nombrar los archivos de imagen obtenidos.
Ese comando, por tanto extraerá las imágenes y las guardará en los
archivos nombrados de pagina-000.png hasta pagina-015.png. Si
los nombres de los archivos ya estaban siendo utilizados, pdfimages
los sobrescribirá, por lo que hay que ser cuidadoso para no
machacar otros trabajos anteriores. Recuerda que cada vez que hagas
un proceso de estos se reiniciará la numeración.
Convertir la imagen en texto: OCR
OCR significa reconocimiento óptico de caracteres por sus
iniciales en inglés. Consiste en generar texto a partir de una
«fotografía» del mismo.
El programa que utilizo es tesseract. Explicaré su uso, como en el
caso anterior, como si lo llamara desde línea de comandos, que tendría
la forma:
tesseract -l epo imagen.png fichero
Veamos las opciones:
-l epo- selecciona el lenguaje, en este caso
epoes el código para Esperanto, pues utiliza el formato códigos de lenguaje de 3 caracteres (ISO 639-2). Para español seráspao para ingléseng. Seleccionar el lenguaje es importante porque automáticamente activa el conjunto de caracteres que buscar y el diccionario de la lengua correspondiente. Si la imagen contiene varios idiomas se pueden encadenar utilizando el+, por ejemplo:-l epo+spa+eng. imagen.png- El archivo de imagen que vamos a procesar.
fichero- es el nombre del archivo donde se guardará el texto. Si
no se especifica nada, creará el archivo
fichero.txt. Si se establece otro formato de salida, la extensión utilizada cambiará. Pero para lo que estoy haciendo, nos basta con texto plano.
Automatización del proceso
Ir haciendo todo ese proceso página a página, para cualquier libro, es
un trabajo monótono y sujeto a errores. En un libro de más de mil
páginas es la muerte a pellizcos. Hay que automatizarlo para evitar
errores y para tener vida aparte de editar contenido. Además, ya
puestos, lo de automatizar el procesamiento OCR puede servirme para
otros proyectos.
Como usuario habitual de documentos org-mode, la manera que se me
ocurrió es hacer un pequeño módulo que automatice todo el trabajo,
extrayendo imágenes convirtiéndolas en texto plano e insertando éste
en un buffer de Emacs.
(require 'org) (defvar ocr-fichero "") (defvar ocr-inicio 0) (defvar ocr-fin 0) (defvar ocr-idioma "")
Para ello, debemos partir de un buffer org y colocar el cursor en
el lugar donde queremos que se inserte el texto. Hay que tener en
cuenta que si vamos a insertar más de un texto, la posición del cursor
no cambia, lo que hace es insertar a partir de él todo texto que le
vaya suministrando el sistema. ¿De dónde podemos sacar la información
que rellene esas variables? Sencillo: desde org-mode podemos
acceder a las propiedades de un encabezado mediante la función
org-entry-get. Esas propiedades se definen de la siguiente manera en
un buffer org:
* Encabezado :PROPERTIES: :nombre_propiedad_1: valor :nombre_propiedad_2: "otro valor" :nombre_propiedad_3: 0 :END:
En nuestro caso, para cargar las propiedades que dijimos antes creé
una función iniciar:
(defun iniciar () "Iniciar las variables globales para el proceso." (setq ocr-fichero (org-entry-get (point) "fichero")) (setq ocr-inicio (string-to-number (org-entry-get (point) "desde"))) (setq ocr-fin (string-to-number (org-entry-get (point) "hasta"))) (setq ocr-idioma (org-entry-get (point) "idioma")))
No hay mucho que explicar:
pointes el valor con la posición del cursor en un buffer deorg-mode.string-to-number, convierte una cadena de texto en un valor numérico.
Para procesar una página, como expliqué antes, haciéndolo desde la
línea de comandos, debemos dar tres pasos: 1) extraer una página del
fichero convirtiéndola en archivo gráfico, 2) generar el texto
mediante el proceso de OCR y 3) insertarlo en el buffer. Los
mismos pasos los hacemos desde una función:
(defun procesar-pagina (num) "Inserta el texto obtenido al procesar la imagen de la página NUM en el /point/." (message "Procesando la página %s" num) ;; Obtener la imagen con el texto (call-process-shell-command (format "pdfimages -png -f %d -l %d %s pagina" num num ocr-fichero)) ;; Obtener el texto de la imagen (call-process-shell-command (format "tesseract -l %s pagina-000.png temporal" ocr-idioma)) ;; Meter el texto en el punto (insert-file-contents "temporal.txt") ;; Borrar los ficheros temporales (shell-command "rm pagina-000.png temporal.txt"))
Para hacerlo, vemos que llama a las aplicaciones externas con la
función call-process-shell-command, o shell-command. Esta función
necesita como parámetro una cadena que se corresponda con el comando
deseado. La cadena se genera con format utilizando una cadena
cargada con elementos como %d para aceptar decimales o %s para
aceptar cadenas luego sustituye esos elementos por los valores que se
pasan como argumentos en la misma llamada a format.
Los comandos anteriores generan un fichero gráfico de nombre
pagina-000.png y el archivo de texto. La función
insert-file-contents inserta en la posición del cursor el contenido
que se encuentre en temporal.txt. El último paso, una vez tenemos
los datos cargados en el buffer de Emacs, a continuación podemos
descartar esos archivos y los borro.
Hacer sólo una página no soluciona mucho, tendría que hacerse por lotes. Para ello sólo hay que llamar a la función anterior una vez por cada página de la que queremos extraer el texto:
(defun procesar-ocr () "Procesa las páginas especificadas del documento dado en el buffer actual." (interactive) (iniciar) ; Establece las variables globales (mapc 'procesar-pagina (number-sequence ocr-fin ocr-inicio -1)))
Esta función es la que llamaremos desde nuestro buffer org para
realizar el proceso completo. Por ello, la definimos para Emacs como
interactive, permitiéndonos llamarla como a cualquier otra función
del editor con M-x procesar-ocr. Lo primero que hace la función es
llamar a la función iniciar que vimos antes para establecer los
valores de trabajo.
La función mapc realiza una llamada a procesar-página por cada
valor devuelto por la función number-sequence. Hay que remarcar que
el recorrido lo hago de ocr-fin a ocr-inicio con un incremento de
-1. Es decir, como los textos se van a ir insertando a partir de la
posición del cursor y los últimos empujarán a los primeros, lo que
quiero es que inserte primero las últimas páginas porque las irá
empujando hacia el final según vaya procesando otras.
Para una visión más completa del módulo, pongo el código completo:
;;; package --- Summary ;;; Commentary: ;;: `procesar-ocr' realiza la conversión de un pdf compuesto de ;;; imágenes a texto plano, incrustándolo después en un /buffer/ org. ;;; Code: (require 'org) ;; Variables globales para el proceso (defvar ocr-fichero "" "Variable que contiene el nombre de ocr-fichero a convertir. En el archivo `org' donde se guardará el resultado, debe estar en una propiedad llamada `fichero'.") (defvar ocr-inicio 0 "Número de página donde comenzar la conversión.") (defvar ocr-fin 0 "Número de página donde finalizar la conversión.") (defvar ocr-idioma "" "Lenguaje de la lista de `tesseract --listlangs`.") ; TODO - Habría que comprobar que existen esas propiedades. ; la función `org-entry-get' devuelve una cadena vacía si la propiedad existe o ; pero está vacía o `nil' si no existe. No sé cómo se tomarán estas aplicaciones ; la falta de un parámetro. (defun iniciar () "Iniciar las variables globales para el proceso." (setq ocr-fichero (org-entry-get (point) "fichero")) (setq ocr-inicio (string-to-number (org-entry-get (point) "desde"))) (setq ocr-fin (string-to-number (org-entry-get (point) "hasta"))) (setq ocr-idioma (org-entry-get (point) "idioma"))) (defun procesar-pagina (num) "Inserta el texto obtenido al procesar la imagen de la página NUM en el /point/." (message "Procesando la página %s" num) ;; Obtener la imagen con el texto (call-process-shell-command (format "pdfimages -png -f %d -l %d %s pagina" num num ocr-fichero)) ;; Obtener el texto de la imagen (call-process-shell-command (format "tesseract -l %s pagina-000.png temporal" ocr-idioma)) ;; Meter el texto en el punto (insert-file-contents "temporal.txt") ;; Borrar los ficheros temporales (shell-command "rm pagina-000.png temporal.txt")) (defun procesar-ocr () "Procesa las páginas especificadas del documento dado en el buffer actual." (interactive) (iniciar) ; Establece las variables globales (mapc 'procesar-pagina (number-sequence ocr-fin ocr-inicio -1))) (provide 'procesar-ocr) ;;; procesar-ocr.el ends here
La plantilla para crear un fichero nuevo a partir del proceso de OCR
está en el archivo plantilla.org del directorio raíz del proyecto,
junto procesar-ocr.el. El contenido es sencillo:
#+setupfile: ../../plantillas/kunularo.org #+include: ./indice.org * Plantilla :properties: :desde: 0 :hasta: 1 :fichero: ../../Tolkien-la-kunularo-de-la-ringoj.pdf :idioma: epo :end:
Puesto que estoy haciendo el libro por capítulos, el procedimiento aquí contado se resume en:
- Copiar el archivo
plantilla.orgcomochapitroXX.org. - Realizar los ajustes de las propiedades y el título del capítulo.
- Llamar a
procesar-ocr. - Corregir errores (los grandes que se ven a simple vista).
- Pasar el diccionario para Esperanto con el
ispellde Emacs. - Generar los archivos
htmlllamando aorg-publish.
Fuentes para Esperanto
Otra dificultad que me encuentro con este proyecto es la elección de fuentes. No todas, especialmente las más vistosas, tienen las ĉapelitaj literoj del Esperanto. Muchas, ni siquiera tienen las eñes o las vocales acentuadas. Después de buscar un poco, encontré Palladio, que tiene un aspecto agradable y una buena colección de glifos. Además se distribuye con licencia libre.
Más problemáticas fueron las fuentes especiales. Por un lado, una de ellas también se distribuye de manera libre. En la fuente Ringbearer se encuentran los glifos para las eñes y las tildes del español, pero no las correspondientes al Esperanto... así pues, vamos poner sombrero a algunas letras:
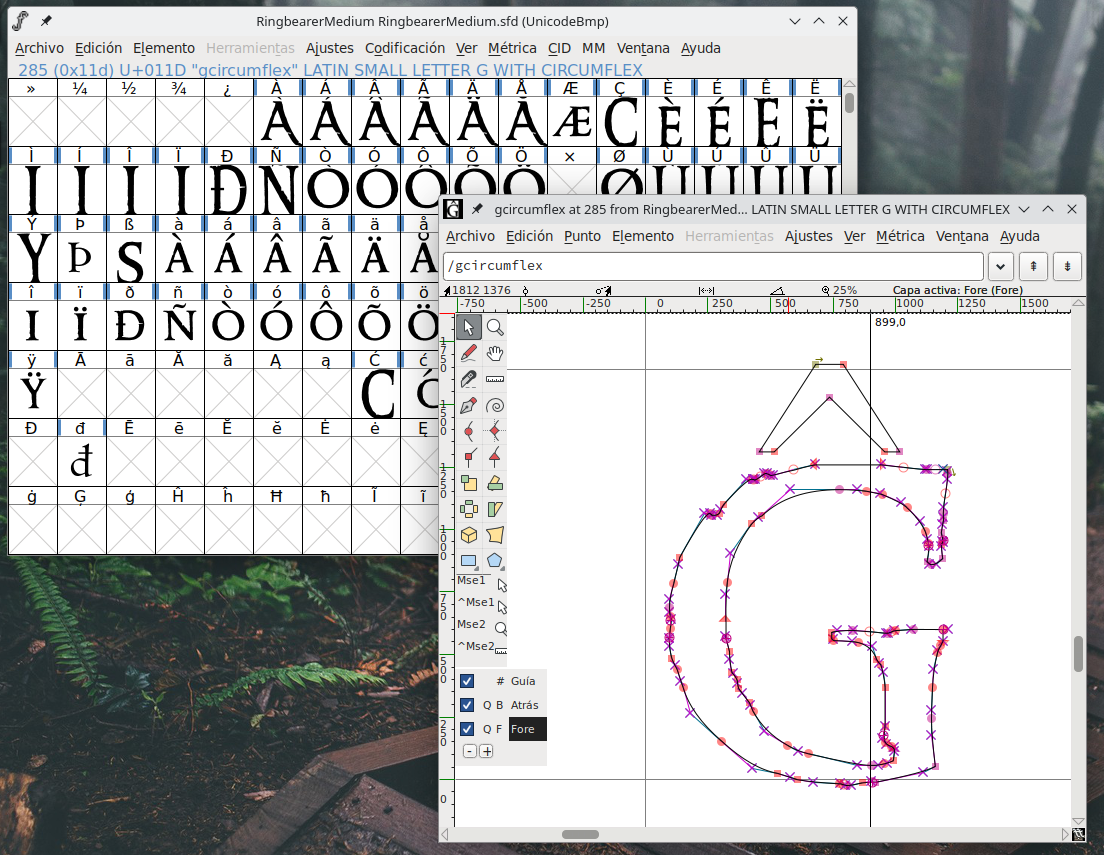
Para la otra fuente utilizada, sin embargo, no he encontrado con qué licencia se distribuye. Es más, tampoco tiene, ni siquiera, los glifos de eñes y tildes. Sólo pone que es free donde la encontré, pero sin saber exactamente la licencia es complicado establecer si puedo modificarla legalmente o no. En todo caso, y como es un proyecto privado, que no se va a publicar no creo que me persigan.
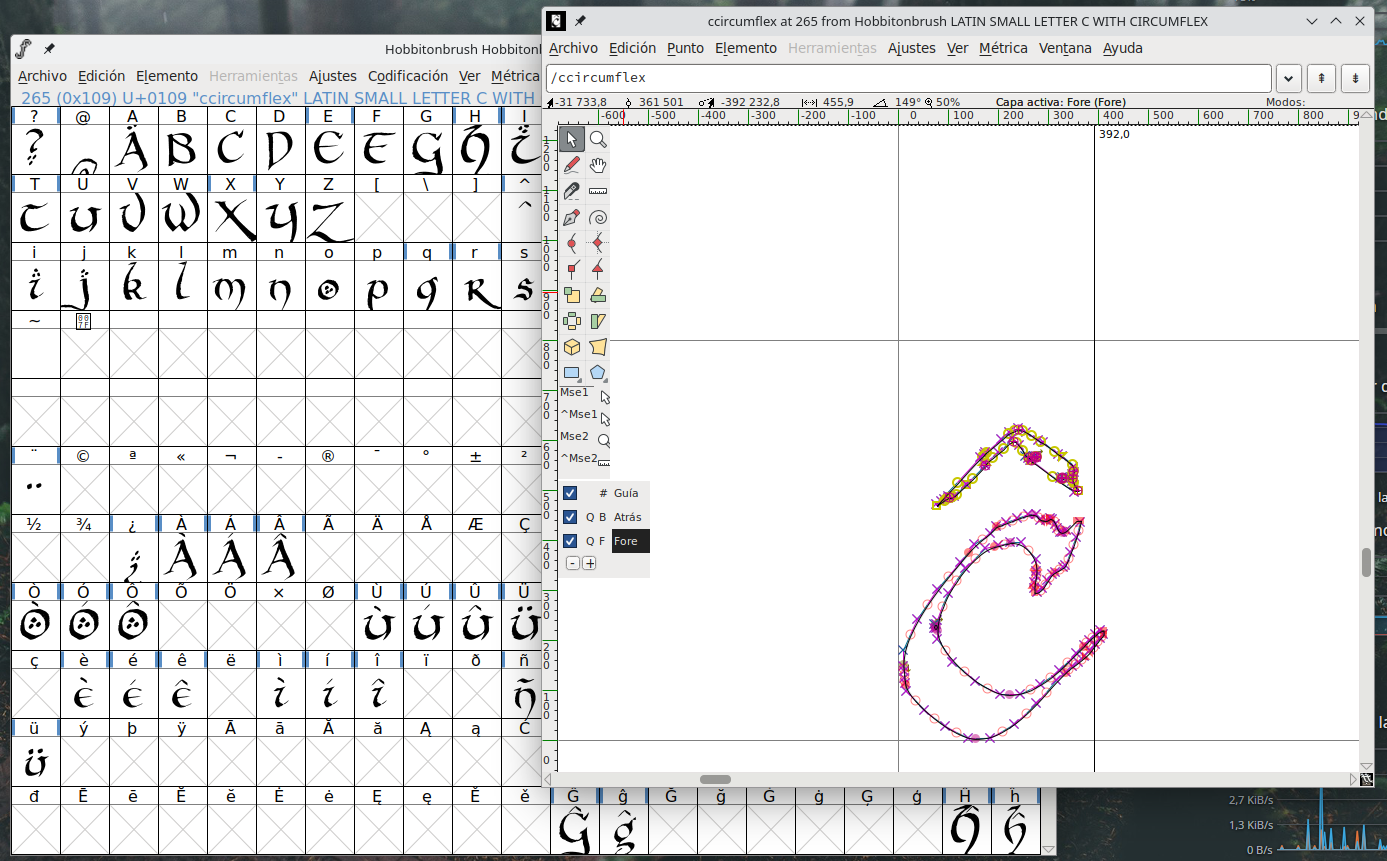
Conclusiones
El objetivo de este tipo de proyectos es aprender a hacer las cosas,
pero también quiero conseguir documentos electrónicos modificables y
editables. Tengo bastantes archivos de este estilo: archivos pdf
compuestos de las imágenes escaneadas de las páginas de un libro. He
elegido éste en concreto porque es un proyecto más complejo que otros:
- Varios tipos de letra.
- Lenguas distintas con otros alfabetos.
- Imágenes.
Su destino será estar en un pequeño servidor doméstico y poder leer tranquilamente con cualquier dispositivo. Sentarme en el sofá o en el sillón, conectarme al wifi y abrir el navegador, ya sea con la tablet, el móvil o el ordenador, sin necesitar instalar ninguna aplicación especial.




{kind=link}
{kind=link}
{kind=link}
Comentarios