
Convertir un pdf en imágenes a texto en org-mode
Llega el verano y estoy preparando mi lector de libros electrónicos y
mi tablet para la lectura estival. Normalmente leo mucho, pero en
verano aún más. Tengo toda una lista de libros para cargar en los
dispositivos, la mayoría en formato epub, otros en pdf. Aquí es
donde empiezan los problemas con los formatos: pdf es un formato que
se inventó para imprimir en papel; si tienes una pantalla del tamaño
mínimo de una hoja de papel lo verás bien; si no, leer un libro en
pdf se convertirá en un suplicio. De hecho, en la tablet según qué
ficheros los puedo leer más o menos decentemente, pero otros no. El
contenido del archivo no se ajusta a la pantalla y se hace incómodo
leer, pasar página, etc. En el libro electrónico, ese cacharrito con
pantalla de «tinta electrónica» del tamaño de un móvil grande o de una
tablet pequeña, los pdf se convierten en una tortura.
Se pueden convertir los pdf a texto de forma fácil, si el pdf
contiene texto. Que puede parecer una tontería, pero hay muchos pdf
que en realidad son una serie de imágenes de páginas escaneadas y
cuando los abres para mirar sólo contienen una ristra de imágenes.
Me gustaría que existiera algún modo de hacer que el pdf se
convirtiera en epub de forma «automágica», pero no conozco ninguna
herramienta que lo haga. Por otro lado, después de pegarme con el
asunto un poco, la complejidad del problema es grande, porque envuelve
tener una conversión de imagen a texto utilizando OCR y aunque los
OCR han avanzado mucho, la salida del texto está plagada de errores:
manchas en el escaneo, saltos de línea en medio de palabras, errores
de codificación como confundir la «m» con «ni» o la «l» con el «1», o
al revés.
La conversión por tanto la debemos hacer por pasos y supervisar los resultados:
- Extraer las imágenes.
- Convertir en texto
- Supervisar y corregir los errores.
Así pues, vamos por partes.
Proceso manual
Vamos a suponer que lo hacemos todo a mano, página a página. Los pasos serían los siguientes.
Extraer las imágenes con poppler-tools
Estas son unas herramientas similares a pdftk, concretamente un
fork de xpdf y entre otras cosas nos permitirá extraer las
imágenes que componen el pdf utilizando la herramienta pdfimages.
Para extraer páginas con pdfimages la línea de comandos es sencilla
de explicar:
pdfimages -png -f 41 -l 50 archivo-origen.pdf nombre-base
Suponiendo que el archivo-origen.pdf es el que deseamos convertir,
la opción -png indica el tipo de fichero gráfico que se generará. La
opción -f 41 indica que comience a extraer (first) en la página 41
y la opción l 50 indica que deje de hacerlo (last) en la 50. El
parámetro nombre-base hará que las páginas convertidas en gráficos
tengan los nombres de fichero nombre-base-000.png hasta
nombre-base-009.png. Como se puede apreciar, la herramienta comienza
la cuenta siempre desde cero, por lo que tenemos que tener cuidado si
no queremos sobrescribir los ficheros con otros.
Convertir la imagen en texto con tesseract
En el momento en que hemos extraído una imagen con el texto es el
momento de que el OCR haga su magia y lo convierta en algo legible.
tesseract -l lang pagina.png fichero-salida
También es una línea sencilla de entender, está el comando tesseract
y las opciones casi se explican solas: la opción -l lang
especifica el idioma en el que se encuentra el texto que se debe
extraer. La opción pagina.png es la imagen escaneada y
fichero-salida es el nombre de fichero que se convertirá en
fichero-salida.txt cuando el OCR haya terminado.
Con esos dos comandos, pdfimages y tesseract, consigo el texto
plano. Pero la pregunta fundamental es: ¿Página a página?.
Automatizar el proceso
Ir página a página está bien si son ficheros cortos de tres o cuatro páginas. Sin embargo, un libro es harina de otro costal, cientos, o quizá miles, de páginas una a una es la muerte a pellizcos. Así que habrá que hacer un procesamiento por lotes.
Voy a explicar todo el proceso según lo voy haciendo desde cero,
comenzando por análisis del problema hasta la codificación de un
sencillo módulo .el que nos haga el trabajo más o menos
«automágicamente».
Análisis del problema
Un libro tiene una estructura de árbol en su índice (también puede
tener forma de árbol muerto en su construcción, pero de momento nos
quedaremos con los electrónicos). Es decir, se estructura en partes,
en capítulos y secciones, subsecciones, párrafos. Algo que explora muy
bien org-mode y que no hace falta que nos detengamos demasiado en
ello. En mi caso he decidido que cada capítulo de un libro vaya en un
documento org aparte.
Estoy tomando uno de los libros que tengo para convertir y haremos un capítulo para las pruebas:
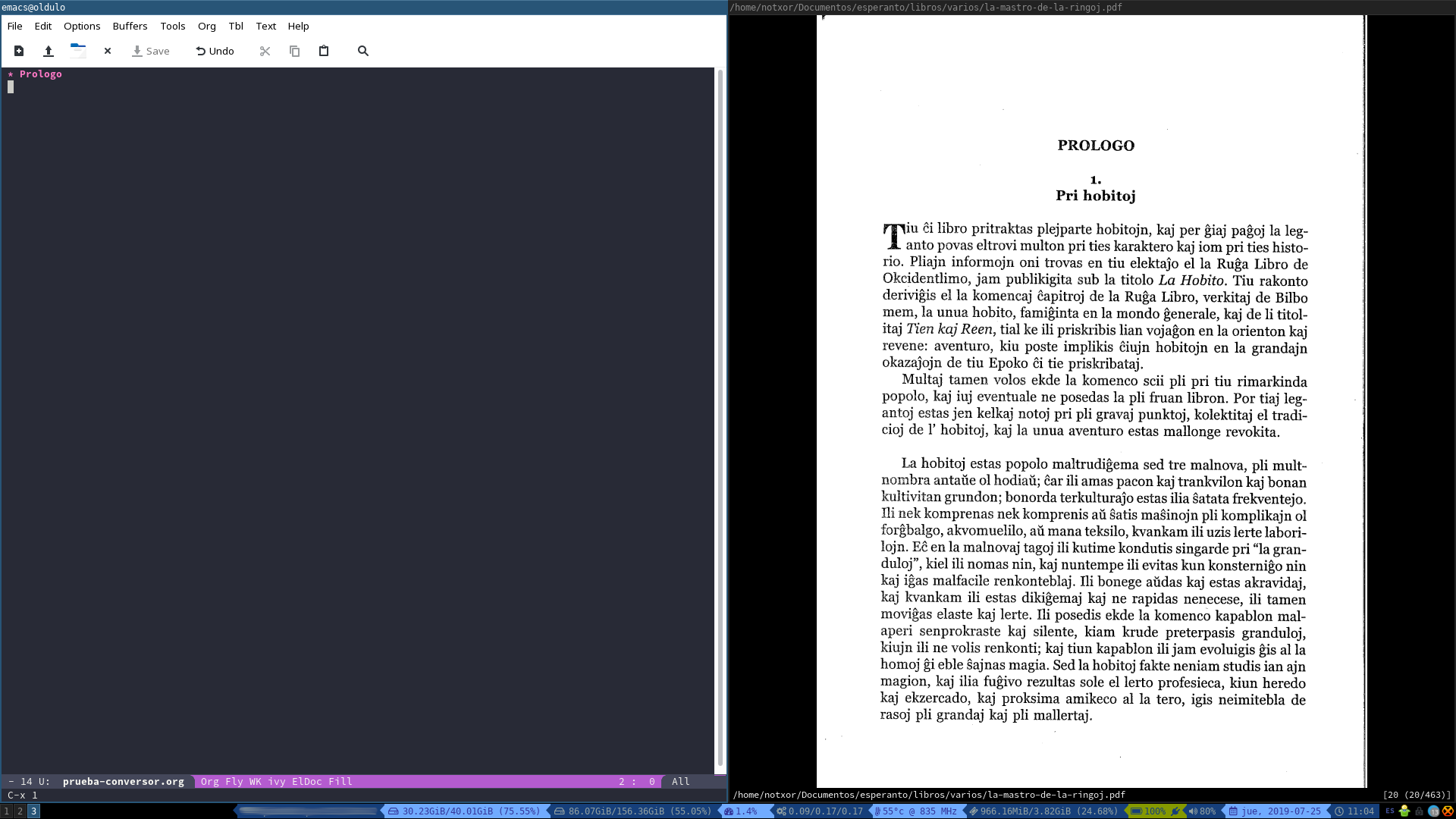
En el visor de la derecha, zathura, nos indica que el capítulo que
queremos convertir comienza en la página 20 así que podemos darle a
nuestra entrada del árbol una propiedad con C-c C-x P y luego
teclearemos en la línea desde: 20 y repetir el proceso con todas las
propiedades que necesitamos. En un principio, el nombre del fichero
original, dónde empezar la conversión, dónde parar y el idioma en el
que está el texto. Esto último es importante porque el OCR se
adaptará al alfabeto y ortografía del texto. Nos deberá quedar algo
así:

Como se puede apreciar el texto para convertir los documentos es bastante sensible:
:PROPERTIES: :desde: 20 :hasta: 34 :fichero: ./la-mastro-de-la-ringoj.pdf :idioma: epo :END:
Vamos al código que hará la conversión por lotes y lo analizaré con todo detalle:
;;; procesar-ocr.el ;; Variables globales para el proceso (defvar fichero "" "Variable que contiene el nombre de fichero a convertir.") (defvar inicio 0 "Número de página donde comenzar la conversión.") (defvar fin 0 "Número de página donde finalizar la conversión.") (defvar idioma "" "Lenguaje de la lista de `tesseract --listlangs`") ; TODO - Habría que comprobar que existen esas propiedades (defun iniciar () "Iniciar las variables globales para el proceso." (setq fichero (org-entry-get (point) "fichero")) (setq inicio (string-to-number (org-entry-get (point) "desde"))) (setq fin (string-to-number (org-entry-get (point) "hasta"))) (setq idioma (org-entry-get (point) "idioma"))) (defun procesar-pagina (num) "Inserta el texto obtenido al procesar una imagen en el /point/." (message "Procesando la página %s" num) ;; Obtener la imagen con el texto (call-process-shell-command (format "pdfimages -png -f %d -l %d %s pagina" num num fichero)) ;; Obtener el texto de la imagen (call-process-shell-command (format "tesseract -l %s pagina-000.png temporal" idioma)) ;; Meter el texto en el punto (insert-file-contents "temporal.txt") ;; Borrar los ficheros temporales (shell-command "rm pagina-000.png temporal.txt")) (defun procesar-ocr () "Procesa las páginas especificadas del documento dado en el buffer actual." (interactive) (iniciar) ; Establece las variables globales (mapc 'procesar-pagina (number-sequence fin inicio -1)))
Iniciar el proceso
La función interactiva, la que se convierte en comando de emacs
es la función procesar-ocr. Es muy sencilla, sólo hace tres cosas:
- Se declara como interactiva.
- Inicia los datos con los valores de las propiedades expresadas en el buffer desde el que se llama.
- Genera una lista con los números de página que tiene que procesar.
Este último punto lo explicaré más despacio: esto es Lisp, esconde
un bucle. Si vienes de otros lenguajes de programación es posible
que viendo procesar-pagina estés esperando algún tipo de bucle. Sin
embargo, en este caso lo que hacemos es utilizar mapc para que
aplique procesar-pagina a una lista con el número de páginas. Los
números se los pasamos en una lista generada por la forma
(number-sequence fin inicio -1) que devuelve una lista desde fin
a inicio con un paso -1. ¿Por qué lo hago al revés? Pues porque
luego, al insertar el texto en el lugar del cursor, emacs irá
empujando hacia abajo lo insertado. Pero no adelantemos
acontecimientos.
El proceso de la página
La función procesar-pagina sólo necesita el parámetro con el número
de página.
He utilizado la forma call-process-shell-command porque la llamada a
shell-command que suele ser más habitual se hace de forma
asíncrona. Eso hace que, dado que el sistema OCR tarda unos segundos
en hacer la conversión y como utilizamos siempre los mismos ficheros
intermedios, una llamada los sobrescribiría cuando aún no ha terminado de
procesarlos la anterior.
Una vez generado el texto se inserta en la posición del punto
(point) con la forma insert-file-contents.
Et voilà
Conseguida la conversión
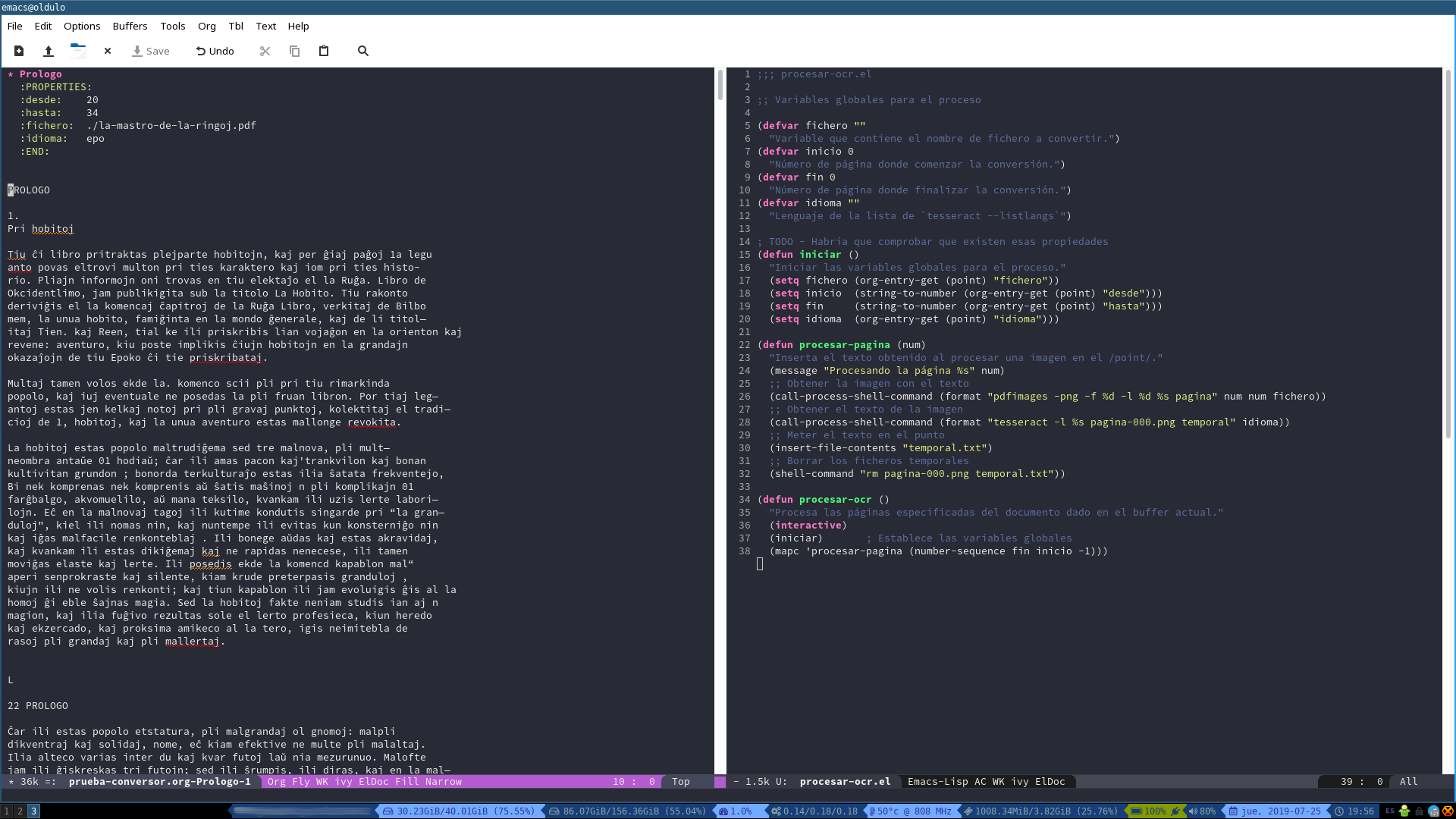
Ahora toca arreglar todos los errores de conversión, eliminar los espacios en blanco sobrantes, los guiones que marcan la continuidad de las palabras en la línea siguiente, los signos de puntuación mal colocados o equivocados, arreglar los párrafos, introducir los formatos de texto: cursivas, negritas, etc. Un trabajo largo y aburrido, pero más sencillo que ir haciéndolo página a página. Y bastante más corto que pasar todo el texto a mano, por supuesto.




Comentarios