
Mis impresiones sobre erlang
Ya conocía erlang desde hace tiempo. Lo conocía de nombre, lo había cotilleado con anterioridad e incluso quise aprenderlo hace unos años, cuando estaba más metido en las cosas 3D y conocí Wings3d (un modelador 3D hecho en erlang). Creo que esto ya lo conté por aquí, pero lo pongo en contexto por si alguien llega a leer este artículo de nuevas.
No es el lenguaje más popular del mundo, más bien es un lenguaje
raro, con unas características un poco extrañas para quien se
aproxima(ba) por primera vez a él, que poco o nada sabía de esos
esotéricos lenguajes funcionales, más allá de las viejas referencias a
LISP. Y así, en su día, la sintaxis, acostumbrado a otras más
encerradas entre llaves o dominadas por bloques indentados, me pareció
un poco marciana; su forma de nombrar las funciones con la
estructura nombre_función/0, donde se especifica el número de
parámetros en el mismo nombre, me pareció hasta fea. Pero, después de
un tiempo utilizándolo todo cambia y, ahora, ha llegado el momento de
que os cansine con mis apreciaciones sobre el lenguaje. Pensaréis:
¿de qué me sirve la opinión de un psicólogo sobre un lenguaje de
programación? La respuesta es sencilla: de nada... ¿qué haces leyendo
esto? O sí, bueno, eres muy libre de seguir si quieres ;-þ
erlang/OTP
Si nunca habéis utilizado erlang es posible que lo de OTP sea nuevo para vosotros. Sin embargo, muchos de los programadores de erlang lo consideran inseparable y usan el lenguaje precisamente por las características de que le dota OTP, como otra capa de abstracción.
Por decirlo de algún modo sencillo de entender, OTP es una librería que viene a facilitar la vida del programador dotándolo de todas las abstracciones que aprovechan las características de erlang sin necesidad de reinventar la rueda en cada aplicación. Luego lo veremos más despacio, pero empecemos por el principio.
¿Qué es erlang?
Erlang es un lenguaje funcional, con tipado dinámico y asignación única. Os sonará lo de tipado dinámico de otros lenguajes, pero seguro que lo de la asignación única os suena marciano ─como a mí al principio─. Esto último consiste en que una vez asignado un valor a una variable, éste no puede cambiar. Y pensaréis: ¿De qué sirven variables que son invariables? ¿unas variables, constantes? ... bueno, yo me lo pregunté en su momento, luego ves que tiene sus ventajas (como que no se produzcan errores porque una variable ha tomado un valor que no debía) y te olvidas de los inconvenientes o más bien de las costumbres que traes de otros lenguajes menos consistentes. Pero veamos las características de las que hace gala:
- Concurrente
- Las aplicaciones de erlang soportan gran cantidad de procesos concurrentes, que no comparten memoria y se comunican mediante mensajes entre ellos.
- Distribuido
- Una máquina virtual de erlang es un nodo. Un sistema distribuido de erlang es una red de nodos cuyos procesos se pueden intercomunicar exactamente igual como lo harían si compartieran nodo. Por eso es fácil levantar varios nodos, incluso en diversas máquinas y nuestra aplicación funcionaría igual que si corriera sobre un sólo procesador.
- Robustez
- Una de las máximas de erlang dice: Deja que falle. Los procesos pueden configurarse de manera que se pueden derivar entre nodos y migrar a nodos que se han recuperado. Unos procesos pueden monitorizar a otros y actuar en consecuencias cuando un proceso falla.
- Soft real-time
- erlang soporta sistemas que requieren tiempos de reacción del orden de los milisegundos.
- Actualización de código en caliente
- Es posible modificar el código que se está ejecutando sin necesidad de detener el sistema.
- Interfaces externas
- los procesos de erlang se pueden comunicar con librerías y otros códigos, hechos en otros lenguajes, con el mismo mecanismo que se utiliza internamente entre procesos. Además, se pueden enlazar programas escritos, por ejemplo en C, dentro del código erlang.
Programación funcional para línea de comandos
Si tienes erlang instalado, verás que viene con algunas herramientas
con él: por ejemplo el prompt interactivo erl o su herramienta para
scripts: escript.
Vamos a ver un ejemplo, que viene en la misma página de manual de
escript, aunque le daremos también alguna vuelta, para ver cómo
podemos fabricarnos nuestros scripts en este lenguaje.
#!/usr/bin/env escript
%% -*- erlang -*-
%%! -smp enable -sname factorial
main([Cadena]) ->
try
N = list_to_integer(Cadena),
F = fact(N),
io:format("Factorial ~w = ~w\n", [N,F])
catch
_:_ ->
uso()
end;
main(_) ->
uso().
uso() ->
io:format("Uso: factorial entero\n"),
halt(1).
fact(0) -> 1;
fact(N) -> N * fact(N-1).
Vamos a analizar ese código. Lo puedes copiar en un fichero que se
llame factorial y hacerlo ejecutable con chmod si quieres
probarlo.
La primera línea es la clásica llamada al intérprete que debe
ejecutar el script, en nuestro caso escript. La segunda línea es
un aviso para nuestro editor favorito (Emacs) para advertirle que
debe iniciar erlang-mode al editar el fichero. Sí, hay un
erlang-mode para Emacs y parece que es el editor oficioso del
mismo. La tercera línea son opciones de configuración de la máquina
virtual:
- el parámetro
-smp enablese utiliza para compilar utilizando el emuladorSMP, que se utiliza para compilar código nativo que se debe compilar con el mismo runtime que lo va a ejecutar. - El parámetro
-sname factorial, da nombre al proceso que ejecutará la máquina. Esto nos permite, por ejemplo, levantar un proceso y llamarlo por su nombre. Tiene un equivalente-name, pero en este último caso el formato seránombre@host. Y es muy útil cuando nuestro script lo que hace es levantar un servicio y queremos llamarlo desde otros procesos.
Después, la función main/1 tiene dos partes, la primera se ejecuta
cuando la lista de parámetros viene con un string o cadena
([Cadena]), lo que hace es intentar convertir la cadena a un entero
y si tiene éxito calcula y devuelve el factorial del número con
fact/1, y si no, remite a uso/0 y la segunda significa en
cualquier otro caso llama a uso/0.
Cosas sobre la sintaxis que pueden llamar la atención, o al menos a mí
me llamaron la atención en su momento: Separa partes de la misma
función con el carácter ;, las instrucciones dentro de cada una de
esas partes con , y se marca con un . el final de la definición de
una función. Sin embargo, cuando la instrucción es end, como ésta ya
es un delimitador, en la instrucción anterior no hay que marcarlo.
Eso de definir la función en partes me resulta marciano... eso pensé en su momento. Y aún en día algunas veces me descubro tirando de otra sintaxis más espagueti. Por ejemplo, el código anterior podría haberse escrito también así:
#!/usr/bin/env escript
%% -*- erlang -*-
%%! -smp enable -sname factorial
main(Args) ->
case Args of
[Cadena] ->
try
N = list_to_integer(Cadena),
F = fact(N),
io:format("Factorial ~w = ~w\n", [N,F])
catch
_:_ ->
uso()
end;
_ ->
uso()
end.
uso() ->
io:format("Uso: factorial entero\n"),
halt(1).
fact(N) ->
case N of
0 ->
1;
N when N > 0 ->
N * fact(N-1)
end.
Como se puede ver, se ha metido la evaluación de los casos dentro de
la llamada a la función, dependiendo de los parámetros que llegan a
ella. Además he añadido un poco de programación defensiva en la
función fact/1 de manera que cuando llega un número sólo calcule el
factorial si es positivo (when N > 0). Lo mismo podríamos haber
hecho en el caso anterior. La última línea hubiera sido:
fact(N) when N > 0 -> N * fact(N-1).
Y por último, destacar el uso recursivo de las funciones. Puesto que
para calcular el factorial, la función fact/1 se llama a sí misma
con otro argumento, hasta llegar a 0, hay que darle una condición de
salida a la recursión. En este caso cuando el valor que llega es 0
deja de llamarse a sí misma y devuelve un valor directo 1.
Como se puede apreciar, erlang es un lenguaje muy flexible y parece que siempre encuentras una manera alternativa de hacer las cosas.
Intérprete de comandos y compilador
Además, también disponemos de un intérprete de comandos: erl que nos
permite introducir uno a uno los comandos de erlang que queramos
ejecutar. Básicamente levanta una máquina virtual y nos permite, por
ejemplo, lanzar nuestras aplicaciones o módulos. Podríamos llamarlo
como:
erl -pa ./binarios -eval 'mi_modulo:start().'
De esa manera podemos lanzar un módulo mi_modulo suponiendo que
exista una función start/0 que sea la que inicie el proceso. El
parámetro -pa ./binarios lo que hace es añadir al path del
intérprete el directorio ./binarios que es donde guardamos nuestros
ficheros compilados. O si lo que hemos hecho es una aplicación OTP
se podría llamar con:
erl -pa ./binario -eval 'application:start(mi_aplicacion).'
Hmmm, un momento... ¿binarios?...¿ficheros compilados?... Sí, también compila el código a un formato intermedio llamado beam que es lo que ejecuta la máquina virtual, que se llama BEAM. De hecho, hay otros lenguajes que aprovechan las características de concurrencia y demás bondades de BEAM compilando también a ese bytecode. Uno de los más famosos es elixir.
El compilador que proporciona erlang es erlc. Nuestro código
anterior podría haberse reducido a un módulo con una función a la que
poder llamar:
-module(factorial). -export([fact/1]). fact(0) -> 1; fact(N) when N > 0 -> N * fact(N-1).
Analizando el código vemos primero dos líneas extrañas al comienzo.
-module(factorial). es una directiva que indica que ese módulo se
llama factorial. Ese nombre debe coincidir con el nombre del fichero
(sin la extensión .erl) que lo contiene. La otra directiva
-export([fact/1]). lo que hace es exportar una lista de funciones
que pueden llamarse desde fuera del módulo. En nuestro caso la lista
sólo contiene la función fact/1.
Si guardamos ese código en un fichero que se llame factorial.erl (si
el nombre del fichero y el módulo no coinciden, el compilador se
quejará), lo podemos compilar desde la línea de comandos:
erlc factorial.erl
Y tendremos en el mismo directorio el fichero factorial.beam que es
el binario generado y que, a partir de ese momento, podemos llamar
desde el intérprete, por ejemplo:
$ erl Erlang/OTP 23 [erts-11.0.2] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:1] [hipe] Eshell V11.0.2 (abort with ^G) 1> factorial:fact(5). 120 2> halt().
Como se puede apreciar, la llamada consiste en el nombre del módulo
factorial separado de la función que queremos llamar y sus
argumentos fact(5), con :. Como es el final de la instrucción,
también debemos marcar el final con el ..
Otra forma de compilar es desde el propio intérprete:
$ erl
Erlang/OTP 23 [erts-11.0.2] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:1] [hipe]
Eshell V11.0.2 (abort with ^G)
1> factorial:fact(5).
** exception error: undefined function factorial:fact/1
2> c(factorial).
{ok,factorial}
3> factorial:fact(5).
120
4> halt().
Si no existe el fichero binario e intentamos llamar a la función,
vemos que nos lanza una excepción diciendo que esa función
factorial:fact/1 no existe. En el paso 2 llamamos al compilador
desde el intérprete con c(factorial)., véase que se omite la
extensión del fichero y devuelve una tuple: {ok,factorial}. Ya
tenemos el módulo cargado y lo podemos usar.
Concurrencia
Otros lenguajes de programación tienen un horror de consideraciones para acceder de forma concurrente a los procesos y los recursos. Esos procesos suelen compartir memoria y hay que ponerle banderas que controlen qué proceso accede o tiene el control de ese recurso.
En erlang cualquier función puede convertirse en un proceso al que llamar. Puesto que los procesos no comparten memoria, levantar y llamar tiendo en cuenta apenas dos cosas. Como quizá se entienda mejor con un ejemplo, vamos a ver el siguiente código:
-module(proceso).
-compile(export_all).
procesando() ->
receive
holaaa ->
io:format("¡que por el culo nooo, Manolo!~n"),
procesando();
digame ->
io:format("... que si quiere bolsa!~n"),
procesando();
_ ->
io:format("Pesao'... no se te entiende.~n"),
procesando()
end.
En cualquier otro lenguaje, las recursiones como la anterior serían la pesadilla del programador. Un bucle que entra en recursión infinita... y aquí los programadores lo hacen a propósito... esto es un sin dios. Pero vamos a ver por qué, analicemos el siguiente fragmento de llamadas:
~ $ erl
Eshell V11.0.2 (abort with ^G)
1> c(proceso).
proceso.erl:2: Warning: export_all flag enabled - all functions will be exported
{ok,proceso}
2> Proceso = spawn(proceso, procesando, []).
<0.87.0>
3> Proceso ! digame.
... que si quiere bolsa!
digame
4> Proceso ! "Hola mundo!".
Pesao'... no se te entiende.
"Hola mundo!"
5> Proceso ! holaaa.
¡que por el culo nooo, Manolo!
holaaa
6> halt().
~ $
Una vez compilado el código en la línea 1, levantamos un proceso con
la función spawn/3, a la que pasamos el módulo proceso, la función
procesando y la lista de argumentos [] en nuestro caso. Esa
función (spawn) nos devuelve el identificador de un proceso de
erlang <0.87.0> y luego podemos llamarlo con la sintaxis !.
Sencillo todo, ¿no?
OTP
OTP son las siglas de Open Telecom Platform y puede parecer que
por su nombre sólo serviría para hacer aplicaciones de
telecomunicaciones, pero no sólo para eso sirve. Al contrario, nos
proporciona una serie de comportamientos (behaviours lo llaman) de
nuestros procesos que nos facilitan mucho la vida. Hay varios de estos
behaviours (y se pueden programar propios), por ejemplo:
application, gen_server o supervisor. El primero nos encapsula
una aplicación, que levanta todos los procesos que necesita; el
segundo nos proporciona toda la funcionalidad de un servidor, con
llamadas síncronas y asíncronas; el tercero es un proceso que
supervisa el funcionamiento de otros procesos y puede hacer que se
reinicien tras un fallo, o que paren todos ante un error. Por ejemplo,
si echamos un vistazo a la estructura de la aplicación con la que ando
trasteando para aprender, podemos representarla como algo así:
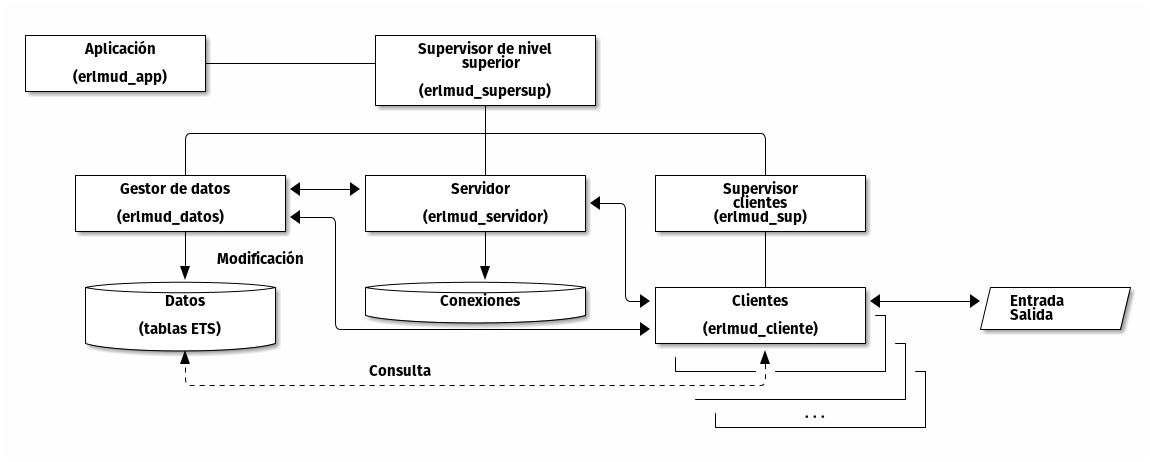
Hay, por encima de todo una aplicación que levanta un supervisor
de nivel superior. Este supervisor, además, levanta un gestor de
datos, un servidor y otro supervisor. Éste último va levantando,
bajo demanda, otros procesos según se conecten los clientes. Aunque
se llamen clientes en realidad es un behaviour de tipo
gen_server, cada uno de esos procesos está dedicado a responder a
las peticiones que llegan desde una determinada conexión TCP por
telnet. En la estructura del MUD, que es lo que estoy programando,
el servidor representa el mundo virtual y envía mensajes a los
clientes con los eventos que ocurren en ese mundo: alguien entra en la
habitación donde estamos, alguien abre o cierra una puerta, amanece o
anochece... etc. Sin embargo, ni el mundo ni los clientes son los
propietarios de los datos: los pueden consultar, pero no
modificar. Cuando necesitan que un dato cambie, le envían la petición
al proceso que los gestiona que es erlmud_datos. Y durante todo el
tiempo, el supervisor de clientes se mantiene a la escucha, por si
llega una nueva conexión por TCP. En el momento en que llega, levanta
un proceso cliente y le pasa los sockets de conexión para que a
partir de ese momento el proceso erlmud_cliente se haga cargo de las
peticiones y =erlmud_sup» vuelve a quedarse de nuevo a la escucha.
Todo el proceso descrito antes apenas se realiza con unas decenas de líneas de código que definen los behaviours y los conectan, las partes escabrosas están encapsuladas por OTP. Luego hay que añadir el código que hace que tu aplicación haga lo que tiene que hacer.
Gestión de datos
En el apartado anterior no quise entrar en mucho detalle en el tema de los datos, pero es una de las cosas que me tienen encantado. En erlang la gestión de datos viene de fábrica. Se pueden emplear tablas cargadas en memoria o en disco con las librerías ETS y DETS (Erlang Term Storage y Disk Erlang Term Storage) respectivamente. Y pueden almacenar gran cantidad de datos. No encuentro exactamente cuánto, pues he visto autores que aseguran que son 4Gb por tabla y otros lo reducen a 2Gb por tabla. En todo caso, para una aplicación normal, puede ser suficiente para funcionar.
Además, las tablas pueden ser privadas (sólo las puede leer-escribir el proceso propietario), pueden estar protegidas (las pueden leer otros procesos pero sólo las puede modificar el propietario, como en mi proyecto de MUD) o públicas (cualquier proceso puede leer y escribir en ellas).
Cualquier tipo de datos que sea correcto para erlang puede meterse en una tabla ets. Por ejemplo, si venimos almacenando los datos en una tuple tipo:
Datos = {12, [1,2,3,4], "una cadena", {ok,42}, 132}.
{_,_,Cadena,_,_} = Datos.
Lista = element(2, Datos).
Podemos ver que la tuple tiene varios campos: un entero, una lista,
una cadena, otra tuple y otro número. Podemos acceder a los datos
dentro por su posición: bien empleando su estructura mediante el
operador de asignación de erlang o bien, utilizando la función
element/2.
Sobre esta capa de almacenamiento erlang introduce otra que es el
record. Que lo que hace, básicamente, es ponerle nombres a los
campos. El equivalente de la tuple anterior sería un record
definido de la siguiente manera:
-record(dato, {id, lista, cadena, tuple, entero}).
Dato = #dato{12, [1,2,3,4], "una cadena", {ok,42},132}.
¿Qué ventaja tiene escribir más? Pues que luego todo es más claro:
Cadena = Dato#dato.cadena. Lista = Dato#dato.lista.
Además, si los datos los tenemos guardados en registros o records, los podemos agrupar en tablas de manera muy sencilla:
ets:new(mis_datos, [set, named_table, protected,
{keypos, #dato.id},
{heir, self(), "Mis Datos"}]).
El código anterior crea una tabla ETS llamada mis_datos. Es un
set, lo que quiere decir que sólo habrá un registro para cada valor
del índice. Se establece que se puede acceder a la tabla utilizando su
nombre con named_table, pero a la vez se establece que está
protegida (protected) y sólo la puede modificar el proceso que la
herede (heir, que este caso es self(), el proceso actual, pero
que podríamos pasárselo a cualquier otro). Y la posición de la clave
(keypos) viene determinada por el campo #dato.id.
Podemos tener tablas de varios tipos: set, bag... cada uno con sus
características, o si lo prefieres con sus ventajas e inconvenientes.
Esto nos permite almacenar nuestros datos de una manera muy accesible
a la par que flexible. En los set cada key sólo aparecerá una
vez, pero en los bag puede aparecer varias veces. En el primer caso,
al buscar una clave en la tabla devolverá una lista con sólo un
registro (si existe la clave en la tabla); y en el segundo caso
devolverá una lista con tantos registros como existan en la tabla, por
poner sólo dos ejemplos.
mnesia
Si no has tenido bastante con las tablas ETS, erlang viene armado
con mnesia que es una base de datos que, como sus primas ETS y DETS,
puede guardar la información en memoria o en disco. Además tiene
limitaciones similares a ETS y DETS en cuanto a capacidad de las
tablas y podría considerarse como una «encapsulación» de ellas. Lo que
proporciona es una forma de consultar registros, guardar esas
consultas y llamarlas cuando lo necesitamos, cruzando tablas si es
preciso. Pero lo más interesante es que proporciona «transacciones»,
de manera que los cambios se producen como «un todo» y si hay algún
error, se anulan todos los cambios de la «transacción» para que no
queden datos inconsistentes.
Lenguaje funcional
Si miramos a qué tipo de programación pertenece el lenguaje erlang encontraremos que en muchos textos lo engloban en los llamados lenguajes funcionales y en general tiene muchas características que hacen que esta clasificación sea adecuada. Aunque en algunos sitios afirman que no es un lenguaje funcional puro, sino que tiene otras características que lo hacen especial.
Entre las estructuras más funcionales tiene en su sintaxis la
capacidad de manejar listas mediante el constructo de «cabecera» y
«cola». El famoso head--tail y que en muchas partes del código de
erlang lo podemos encontrar en accesos marcados como [H|T],
funciones lambda u otras funciones como el famoso map. Por
ejemplo:
-module(prueba).
-export([duplica/1]).
duplica(Lista) ->
lists:map(fun(X) -> X*2 end, Lista).
Si lo llamamos y le trasladamos la lista [1,2,3,4,5] nos devolverá
la lista [2,4,6,8,10]. En el código podemos apreciar la función
lambda que realiza la multiplicación, que viene definida entre las
palabras claves fun y end.
Aunque también hubiéramos podido ahorrarnos toda esa sintaxis y recurrir a la sintaxis de las lists comprehensions, que te sonarán porque se las han copiado otros lenguajes como Python:
Lista = [1,2,3,4,5], [X*2 || X <- Lista].
Mucho más sencillo de leer y ver, ¿no?. O, otro ejemplo por utilizar una función resumen de listas:
~ $ erl Eshell V11.0.2 (abort with ^G) 1> Lista = [1,2,3,4,5]. [1,2,3,4,5] 2> lists:sum([X*2 || X <- Lista]). 30 3>
También podemos filtrar qué elementos nos interesan de la lista, por ejemplo, si queremos hacer las operaciones sólo sobre los impares:
3> [X || X <- [1,2,3,4,5], X rem 2 /= 0]. [1,3,5] 4> [X*2 || X <- [1,2,3,4,5], X rem 2 /= 0]. [2,6,10] 5>
Optimizador del código compilado
Me resisto en llamar a HiPE un JIT, sin embargo, funciona de
manera similar. Hight Performance Erlang es un módulo que puede ser
llamado al compilar para acelerar un poco el código. Sin embargo, esas
mejoras tienen algún inconveniente que hay que valorar y es mejor leer
la documentación para ver si nos compensa.
Llamarlo es sencillo, por ejemplo, al hacer la compilación del módulo desde el prompt interactivo:
~ $ erl
Eshell V11.0.2 (abort with ^G)
1> c(factorial, [native]).
{ok,factorial}
2>
Como se puede ver una forma sencilla de hacerlo, aunque se puede
afinar aún más utilizando las opciones de HiPE llamando a la
compilación con [native, {hipe, Opciones}].
Conclusiones
Después de este ladrillo intentando escribir sobre todo erlang aún sabiendo que es imposible, vienen las conclusiones:
- Me gusta erlang y voy a seguir utilizándolo. Algunas de mis cosas ya se están escribiendo en erlang. Aquellas que no necesitan una interface (que esas siguen corriendo en elisp.
- Es un lenguaje muy flexible y expresivo. Aunque al principio me resultaba un poco marciana la sintaxis una vez acostumbrado a ella me resulta agradable.
- Cuando algo falla, sus informes de error son muy precisos y es muy fácil saber qué ha fallado y dónde. Y los fallos suelen caer de parte de la lógica del programador, porque el no poder modificar las variables implica que nunca el error se debe a que tomen un valor equivocado, ni tienes que estar trazando paso a paso a ver cómo varían.
- Cuando ejecuto el código y levanta varios procesos, estos se
adaptan automáticamente y usan todos los núcleos de la máquina sin
escribir ni una línea para preocuparme de los hilos... ya se ocupa
la
vmde erlang. Lo cual es un descanso para mí.
Pues hasta aquí hemos llegado. Supongo que con un exceso de información para un artículo del blog, pero a la vez escasa para intentar aprender algo. Y todo esto, sólo mientras sigo aprendiendo, porque esto es un mundo de aprendizaje nuevo. De un lenguaje marciano, que no es de los más populares, pero sí uno de los más potentes que he encontrado: capaz de montar sistemas distribuidos con suma facilidad, de sustituir el código sin pararlo todo, de crecer y escalar de forma casi «natural».
Sólo por probar levanté un nodo con cientos de miles de procesos y en una prueba llegué a los dos millones (eso sí, casi quemo el procesador con todos sus núcleos funcionando al 100% durante un buen rato). En una máquina con más memoria y procesador ¿hasta dónde hubiera llegado? No sé, me parece un lenguaje digno de destacar y de ponerlo en valor y por eso he escrito este artículo. Espero que sea útil.
 2012 -
2012 - 