
Cómo trabajar con SQLite3 desde Emacs
En mi último artículo hablé de cómo trabajo en formato texto con Emacs y son varios los que me han preguntado por el apartado de base de datos. ¿Cómo me las apaño para tener las bases de datos de SQLite en modo texto?
Lo primero es confesar que no tengo todas, sino sólamente aquellas que
quiero tener controladas en repositorios git. La otras las guardo en
el fichero de base de datos que genera SQLite, porque es más
sencillo y rápido acceder a los datos así. Pero aunque no las tenga en
formato de texto, sí hay consultas, en mi fichero de consultas, que
las referencias.
Para explicar mejor el proceso que sigo, voy a contar desde cero y pondré también capturas de pantalla, paso a paso.
Crear una base de datos
Lo primero que hago es crear un fichero con el nombre que quiero ─en
el ejemplo lo llamaré base-de-datos, por ejemplo─ y le añado una
extensión sql. Al abrir este fichero, Emacs entrará en modo SQL,
y por defecto se colocará en modo ANSI.
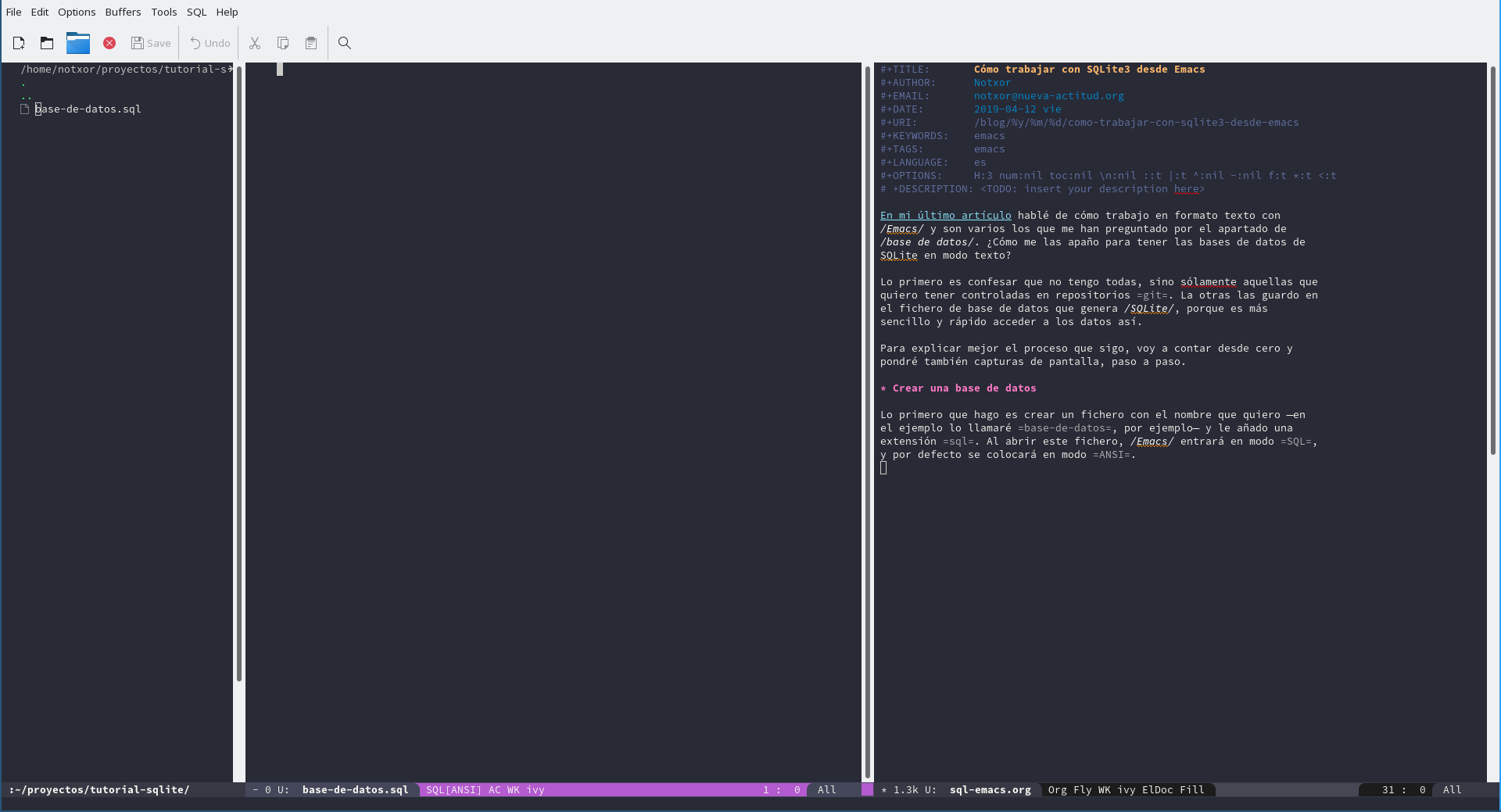
Como se puede ver en la imagen, la barra de estado marca el modo
SQL[ANSI], aunque el archivo aún está vacío. Lo primero es decirle
al editor que vamos a utilizar, concretamente SQLite. Para ello
utilizo el comando M-x sql-set-product RET sqlite RET.
Estando en el buffer del fichero sql, que permanece vacío, vamos a
levantar también un entorno interactivo para SQLite dentro de
Emacs: así no tenemos que estar entrando y saliendo del editor, sino
sólo cambiando de buffer. Para lanzarlo utilizo la combinación de
teclas C-c TAB también se podría llamar mediante M-x
sql-product-interactive. Al lanzarlo nos pide un nombre para la base
de datos, en mi ejemplo base-de-datos.db y nos mostrará el típico
prompt de SQLite.
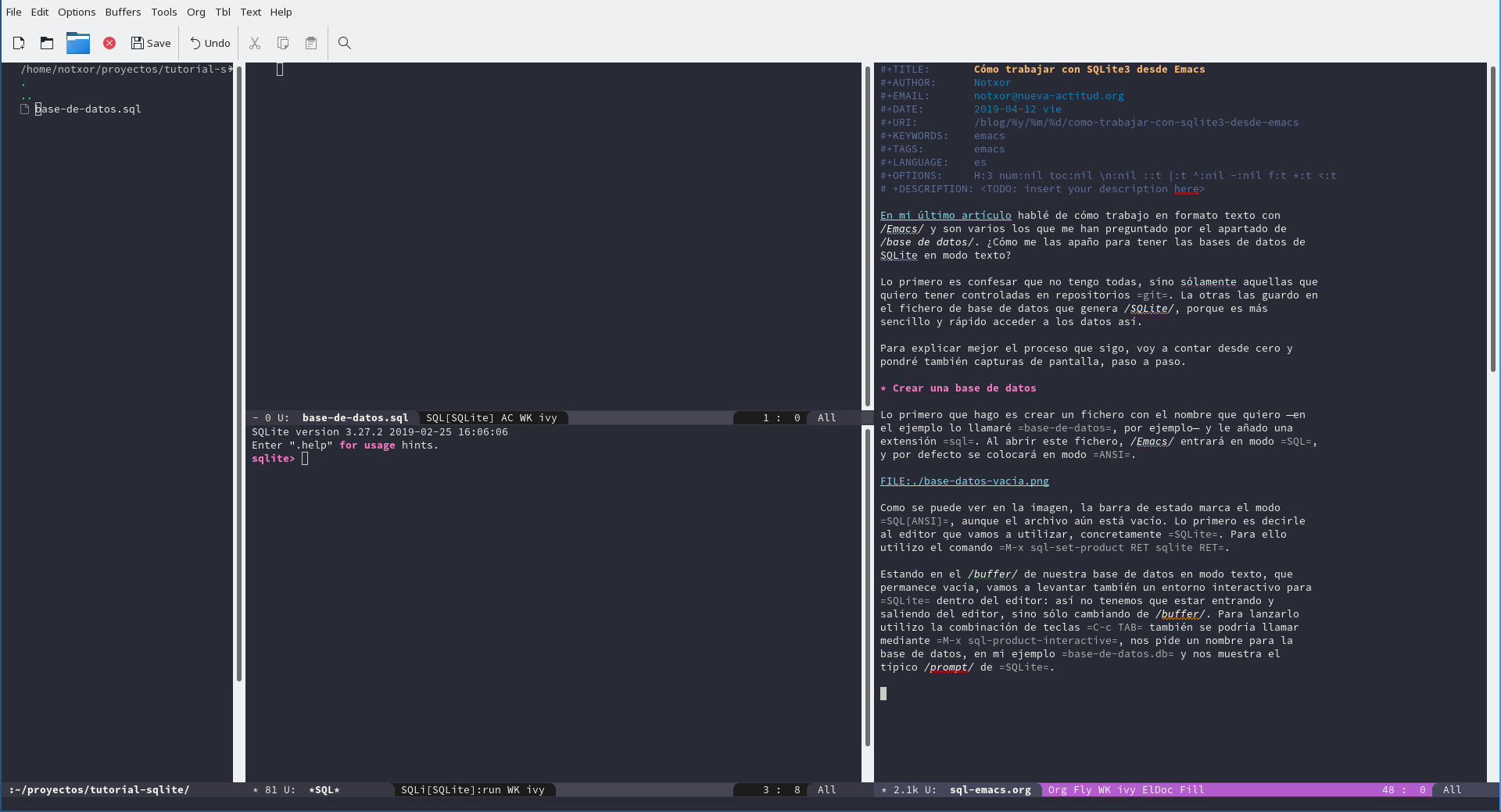
Ahora podemos dar el siguiente paso en cualquier de los dos buffers
pero para mí resulta mucho más sencillo hacerlo directamente en el
interactivo de SQLite. Vamos a crear una tabla dentro de nuestra
base de datos.
CREATE TABLE Gente (
id integer primary key autoincrement,
Nombre text,
Telefono text);
Y para que no esté vacía la base de datos, voy a añadir un par de registros a esa tabla:
insert into Gente(Nombre, Telefono) Values('Pepe', '123456789');
insert into Gente(Nombre, Telefono) Values('Juan', '987654321');
Bien, vamos a hacer una consulta y como me gusta ver las cosas
ordenadas, también añado los comandos .mode column y .headers on
para que se muestren las consultas, como por ejemplo:
SELECT * FROM Gente;
id Nombre Telefono ---------- ---------- ---------- 1 Pepe 123456789 2 Juan 987654321
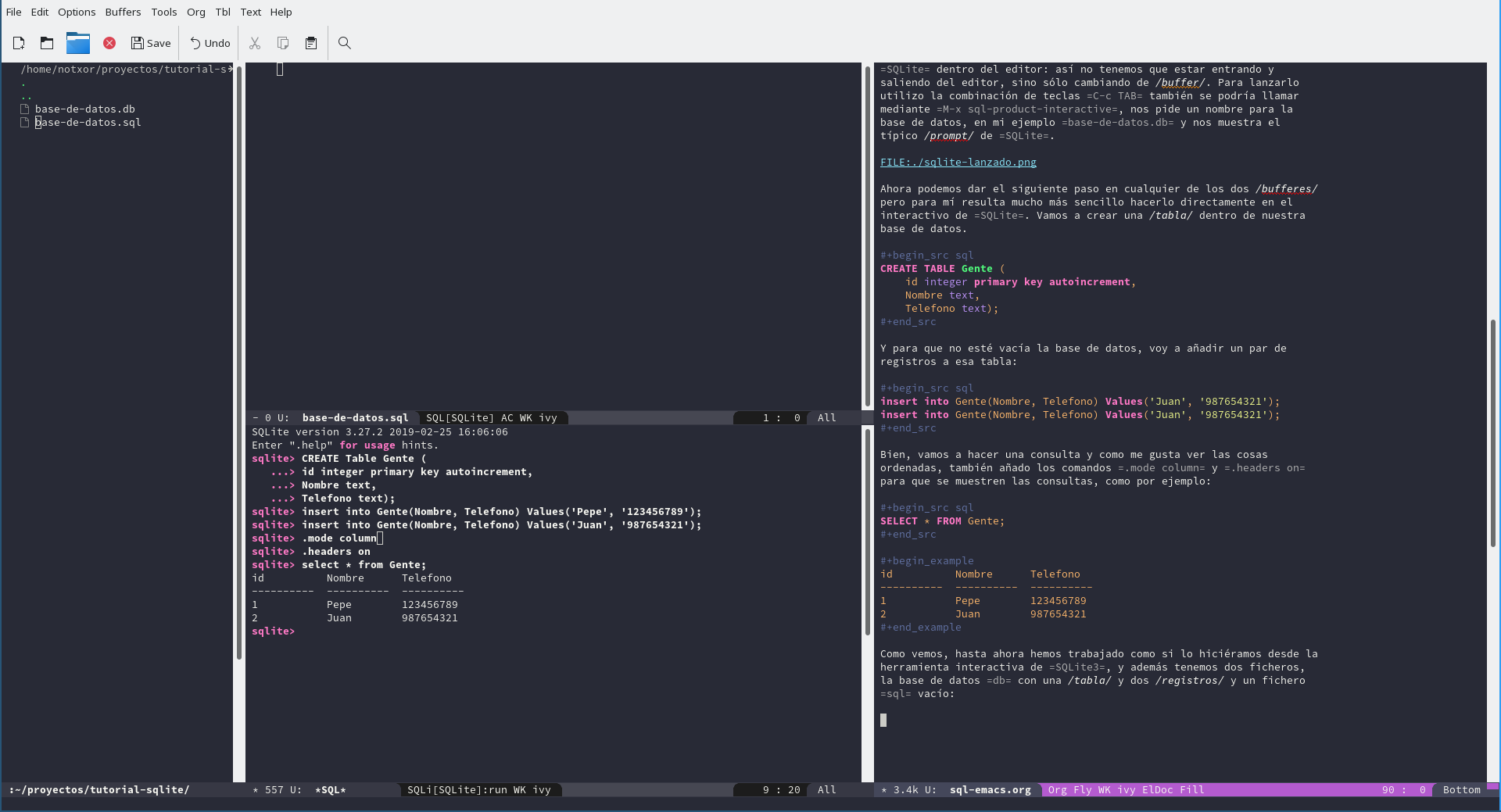
Como vemos, hasta ahora hemos trabajado como si lo hiciéramos desde la
herramienta interactiva de SQLite3, y además tenemos dos ficheros,
la base de datos db con una tabla y dos registros y un fichero
sql vacío:
Convertir la base de datos a texto
Cuando tenemos la base de datos creada la podemos pasar a formato
texto desde el mismo buffer de SQLite con dos sencillos comandos:
.output base-de-datos.sql .dump
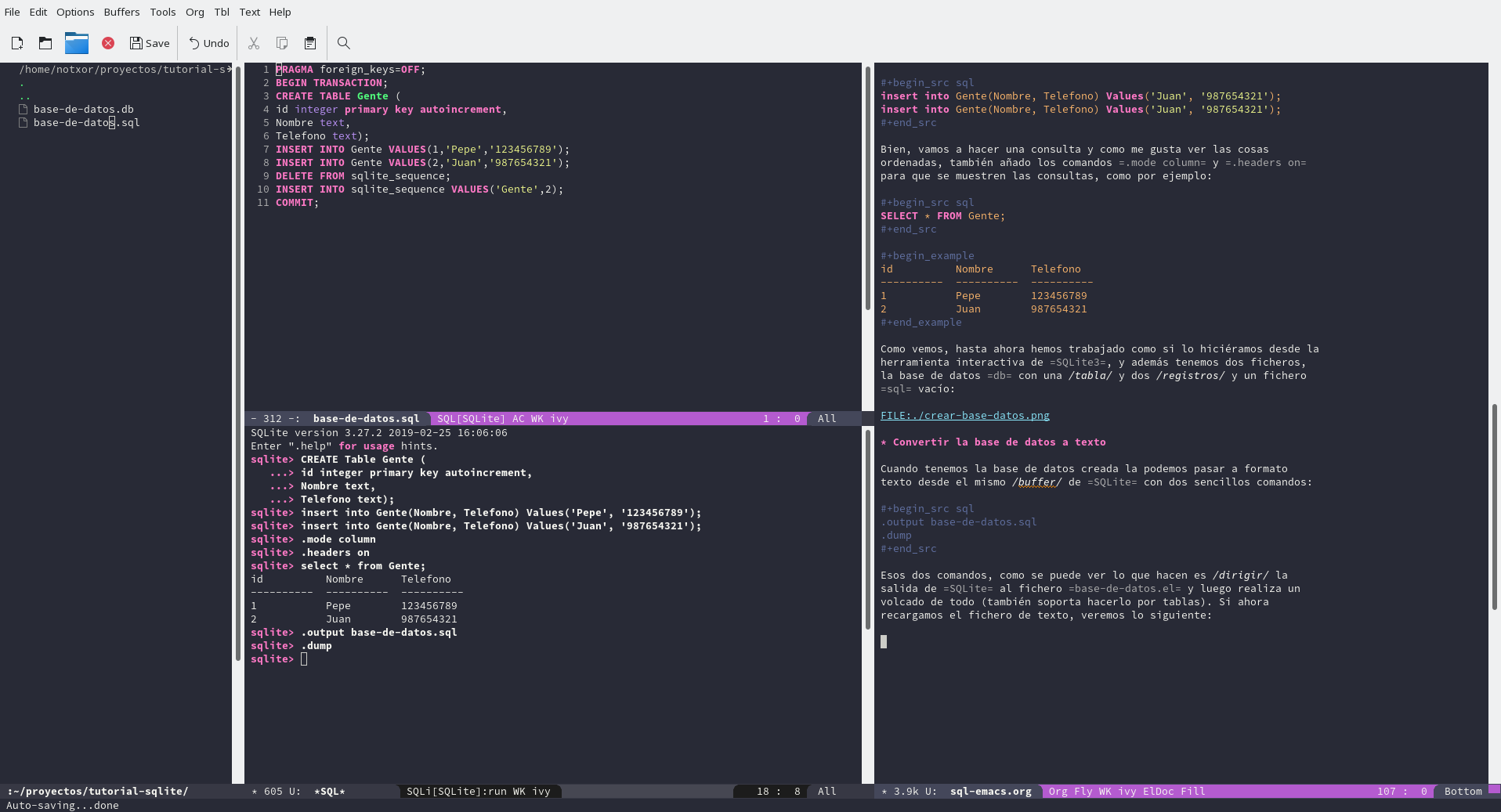
Esos dos comandos, primero lo que hacen es dirigir la salida de
SQLite al fichero base-de-datos.el y luego volcar toda la base de
datos (también soporta hacerlo por tablas). Si ahora recargamos el
fichero de texto, veremos lo siguiente:
Ahora, podemos borrar el fichero binario de base de datos y trabajar
sólo con el sql. Por ejemplo, me he dejado un par de detalles que en
formato de texto se pueden modificar sobre la marcha. En nuestra base
de datos no tendría sentido tener teléfonos sin nombre, o nombres sin
teléfonos, así que debería haber marcado esos campos como NOT
NULL. Así, he modificado el fichero de texto para dejarlo como sigue:
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE Gente (
id integer primary key autoincrement,
Nombre text not null,
Telefono text not null);
INSERT INTO Gente VALUES(1,'Pepe','123456789');
INSERT INTO Gente VALUES(2,'Juan','987654321');
DELETE FROM sqlite_sequence;
INSERT INTO sqlite_sequence VALUES('Gente',2);
COMMIT;
Si borramos la base de datos binaria la podremos recargar desde ese
fichero de texto, generado antes. Vamos a hacer la prueba para
demostrar lo sencillo que es. Volvemos a lanzar el entorno interactivo
desde el buffer de nuestro código sql con C-c TAB y el nombre
del fichero, que podemos utilizar, que puede ser el mismo u otro. Una
vez hecho, si pedimos que nos muestre el .schema de la base de datos
nos dirá que está vacía, pero si desde nuestra base de datos en sql
le lanzamos el buffer con C-c C-b y volvemos a preguntar, ya
veremos nuestra estructura cargada.
Así mismo, si por algún casual una base de datos va a gestionarse
desde un entorno de base de datos, como puede ser MariaDB o
PostgreSQL o el cualquier otro que comprenda el sql, bastaría con
modificar mínimamente ese fichero para ajustarse a las idiosincrasias
de cada base de datos y convertirla con facilidad. Por eso es
recomendable que utilicemos siempre código sql lo más estándar
posible para facilitar luego la exportación de datos.
Fichero para consultas
Ya he explicado un poco por encima cómo funciona el Emacs en modo
sql. En este caso sobre SQLite3, pero se puede conectar a un buen
puñado de bases de datos relacionales.
Además suelo tener en «el cargador» otro fichero que guarda código
para hacer determinadas consultas. La mayoría de esas consultas se
hacen sin cargar el entorno interactivo sin abrir el fichero sql y
es lo que mostré en el artículo anterior, por lo que no me extenderé
en ello demasiado. Por ejemplo:
#+begin_src elisp :export code (require 'sqlite) (let ((db (sqlite-init "~/proyectos/tutorial-sqlite/base-de-datos.db"))) (sqlite-query db ".headers on") (setq resultado (sqlite-query db "select * from Gente")) (sqlite-bye db) resultado) #+end_src #+RESULTS: | id | Nombre | Telefono | | 1 | Pepe | 123456789 | | 2 | Juan | 987654321 |
Guardarlo así me permite generar tablas complejas y que son devueltas
en un formato muy próximo al que puede gestionar org-mode. En el
ejemplo, puesto que se tratan de datos muy básicos y no hay datos
cruzados entre diferentes tablas, puede parecer innecesario. Sin
embargo, cuando la base de datos se complica y/o las consultas
implican varios join o necesitas trabajar los resultados de otra
forma, como llevarlos a un informe, por ejemplo; el tener ese fichero
de consultas es un ahorro de tiempo y quebraderos de cabeza. El
código de consulta sql lo tienes a mano, lo puedes modificar para
ajustarlo a la consulta que necesitas en ese momento y los resultados
los tienes inmediatamente al pulsar C-c C-c en el bloque de código.
 2012 -
2012 - 