
Tipos de datos
Cuando escribimos un programa es porque necesitamos tratar la información como nosotros necesitamos que sea tratada. Esa información es lo que llamamos datos.
En otros lenguajes, los datos y los programas son cosas separadas, sin embargo, en Lisp, los datos y los programas son la misma cosa. Dicho de otro modo, los programas pueden ser tratados como si fueran un tipo de datos más. Ese es el motivo principal de que, como vimos en el artículo anterior, usáramos el «'» para advertir a Lisp cuándo una estructura es un programa o es un dato... ya me perdonaréis por utilizar programa como sinónimo de código ejecutable.
En el código, aparte de programas y datos, existe otro tipo de información: los comentarios. Un comentario es un texto que se añade en el código con el objeto de hacer anotaciones o aclaraciones sobre el funcionamiento del mismo. En una línea, todo texto que aparezca tras un carácter «;», será ignorado por Lisp.
Tipos de datos básicos
Voy a explicar los tipos más habituales y sencillos: números, caracteres, cadenas, cons, secuencias, símbolos. Dejaré los de edición, propios de Emacs, para más adelante en algún ejemplo. Si alguno de los presentes tiene prisa, en la ayuda de Emacs, en el manual de Elisp hay todo un capítulo dedicado a ese tipo de datos.
Datos lógicos
En realidad, todos los datos pueden funcionar como lógicos. También se llaman datos booleanos en referencia al álgebra de Bool. Sólo hay dos valores posibles: verdadero y falso.
Algunos os habréis fijado que en algunos valores que se establecen en el fichero de configuración de Emacs aparecen expresiones como:
(setq variable1 nil) (setq variable2 t)
En ese caso, nil es el valor lógico para falso y t es el valor
lógico para verdadero.
Números
En elisp podemos trabajar con enteros o con decimales. Los números enteros pueden contener un rango mínimo de -536.870.912 a 536.870.911. Es decir, el rango que se pueden utilizar con 30 bits. Si necesitamos números más grandes, Lisp añadirá espacio para contenerlos, por ejemplo, podemos evaluar el siguiente código en el buffer scratch sin obtener un mensaje de error:
(1+ 536870911)
Claro, que lo que hace lo que hace Emacs para cargar ese resultado
es utilizar un número de coma flotante y aunque muestre 536870912
internamente se utilizará el número 536870912.0.
La forma de definir un entero (en base diez) es mediante una secuencia
de cifras precedidas de un signo (+ o -), opcional si el número es
positivo, o también seguido de un . final. Por ejemplo, son números
enteros válidos, junto con lo que devuelven si los evaluamos:
+12 ; ==> 12 -3 ; ==> -3 4. ; ==> 4 200 ; ==> 200
Los números de coma flotante tienen una parte entera y una parte decimal. Veamos cinco formas de escribir el mismo número:
700.0 +7e2 7.0e+2 +7000000e-4 .7e3
Donde e indica una potencia de 10.
Caracteres
Los caracteres los he puesto aparte de los números, no porque
internamente sean algo distinto a un número, sino porque representan
otros contenidos: letras, signos ortográficos o caracteres de control,
por ejemplo. En Emacs los valores que representan caracteres tienen
32 bits. Si el valor es menor de 127 se considera un carácter
ASCII; el resto de valores se consideran no-ASCII.
Hay algunos caracteres especiales que si estás utilizando Emacs y lees sus manuales, estarás acostumbrado a ver escritos en ellos:
?\a ; ==> 7 control-g, ‘C-g’ ?\b ; ==> 8 backspace, <BS>, ‘C-h’ ?\t ; ==> 9 tabulador, <TAB>, ‘C-i’ ?\n ; ==> 10 salto de línea, ‘C-j’ ?\v ; ==> 11 tab. vertical, ‘C-k’ ?\f ; ==> 12 formfeed, ‘C-l’ ?\r ; ==> 13 retorno de carro, <RET>, ‘C-m’ ?\e ; ==> 27 escape, <ESC>, ‘C-[’ ?\s ; ==> 32 espacio, <SPC> ?\\ ; ==> 92 contrabarra, ‘\’ ?\d ; ==> 127 delete, <DEL>
Evidentemente, la forma más habitual de expresar un carácter en
Emacs es escribir el carácter en cuestión anteponiendo un ?, si
evaluamos ?A en el buffer scratch nos devolverá 65, pero también
podemos conseguir ese carácter expresándolo como ?\o101, ?\x41, en
formatos octal y hexadecimal, también puedes utilizar el valor
Unicode ?\u0041 o incluso el nombre de la letra en cuestión, como
en ?\N{latin capital letter A}.
Más interesante que aprenderse la tabla de caracteres unicode es
conocer los caracteres de control. Para ellos podemos utilizar la
notación ^. Por ejemplo, si tomamos el último carácter de la lista
anterior, <DEL>, además de ?\d, podemos utilizar la secuencia
?\^? o incluso la secuencia ?\C-?.
Igual que los caracteres control también podemos acceder a los
caracteres escapados con <META>. Por ejemplo, podemos escapar el
valor ?\M-x o incluso mezclar ambas formas para escribir C-M-c
como ?\M-\C-c, o ?\C-\M-c, o ?\M-\003.
Del mismo modo podemos utilizar las teclas hyper, super y alt,
con los modificadores \H-, \s- y \A-. Por ejemplo, la secuencia
de teclas Alt-Hyper-Meta-x podemos tenerla con ?\H-\M-\A-x.
Numéricamente, los valores son 2^22 para alt, 2^23 para super y
2^24 para hyper.
Símbolos
Un símbolo podemos definirlo como la manera de referirnos a un objeto mediante un nombre.
Un símbolo puede contener cualquier carácter. Lo recomendable es
utilizar letras, dígitos y algún signo de puntuación normal, como
-+=*/ para nombrar nuestras variables y funciones. Aunque tampoco
necesitan una notación especial, los caracteres _~!@$%^&:<>{}?
suelen ser menos utilizados. Cualquier otro carácter se puede utilizar
en un símbolo escapándolo con un carácter \. Pero teniendo en cuenta
que mientras \t en una cadena significa un tabulador, en un símbolo
será sólo la letra t. Por ejemplo:
(setq al\t 22) ; ==> 22 alt ; ==> 22
Tenemos que tener en cuenta alguna limitación. Si escribimos +1
Emacs lo interpretará como el número 1 entero; sin embargo, no habrá
problema en utilizar como nombre 22+, por ejemplo.
Otro detalle a tener en cuenta es que en otros Lisp, como el common
lisp los símbolos uno y UNO son equivalentes, sin embargo en
elisp son dos símbolos diferentes.
En todo caso, siempre es recomendable utilizar nombres que sean fácilmente leídos, escritos y comprendidos; a poder ser, que el nombre sea consecuente con el contenido que le va a ser asignado.
Diccionarios o listas asociativas
En otro artículo de la serie ya hablé de las cons cells y las listas y vimos cómo se pueden crear. Pero hoy voy a hablar de otro de los usos que nos puede ser muy útil: los diccionarios o listas asociativas. Vemos un ejemplo para explicarlo un poco mejor.
(setq colores '((rosa . rojo)
(margarita . amarillo)
(lirio . blanco)
(violeta . azul)))
(cdr (assoc 'rosa colores)) ; ==> rojo
(car (rassoc 'blanco colores)) ; ==> lirio
Como ya hablé de car y cdr no lo repito aquí, se puede uno ir a
ese otro artículo o consultar la ayuda de Emacs (que será más rápido
y exacto).
Como se puede ver, al principio creamos una variable que consiste en
una lista de cons cell asignadas al símbolo colores. Dentro de la
lista podemos buscar el par por el primer elemento o por el
segundo. Si lo hacemos por el primer elemento (o car) utilizamos la
función assoc que devolverá el primer elemento que coincida con el
símbolo buscado. Si buscamos por el segundo elemento (el cdr) hará
lo mismo.
Como (assoc 'rosa colores) devolverá (rosa . rojo), si a mí sólo
me interesa el valor del color, que he almacenado en la posición
cdr, lo que haré será pedirlo con la función cdr. Y al revés, si
busco por colores con (rassoc 'blanco colores), devolverá (lirio
. blanco); si a mí sólo me interesa el nombre de la flor de ese
color, que hemos almacenado en la posición car del par, la pido con
la instrucción car.
Listas de propiedades
Las listas de propiedades (property list o plist para acortar) es una lista de pares de elementos. Normalmente, el nombre de la propiedad es un símbolo que se asociará al valor correspondiente.
Lo vemos también con un ejemplo:
(setq contacto '(nombre "Fulanito"
apellidos "de Tal y Tal"
telefono "987654321"))
(plist-get contacto 'nombre) ; ==> "Fulanito"
(plist-get contacto 'telefono) ; ==> "987654321"
(plist-get contacto 'apellidos) ; ==> "de Tal y Tal"
(plist-put contacto 'poblacion "Madrid")
(plist-get contacto 'poblacion) ; ==> "Madrid"
Como vemos, una lista de propiedades también trabaja asociando valores de pares, pero lo hace sobre cualquier tipo de lista. En el ejemplo se utilizan símbolos para las propiedades y cadenas de texto para los contenidos, pero se pueden utilizar cualquier tipo de datos válidos en elisp, tanto para uno como para el otro.
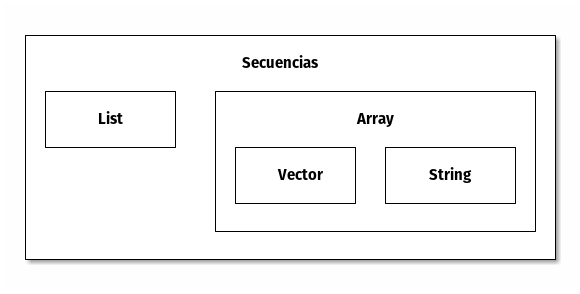
Secuencias
En Lisp es habitual encontrar estructuras de datos que son secuencias. Las más habituales son las cadenas de texto (para abreviar cadenas a secas), los arrays y los vectores.
El siguiente diagrama muestra la relación entre distintos tipos de secuencia.
Acceder a cualquier elemento se puede hacer como sigue a continuación:
(elt '(1 2 3 4) 2) ; ==> 3
Puede llamar la atención que pidiendo la posición 2, nos devuelva el 3. A estas alturas, los lectores programadores tienen la neurona acostumbrada a comenzar a contar índices por el 0. Si no eres programador y te cuesta imaginarte cómo, fíjate en el siguiente esquema:
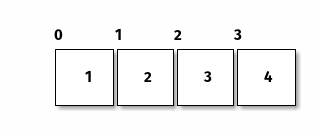
Uno puede pensar en los índices como los indicadores que señalan no a las posiciones sino a la «imaginaria separación» entre ellas.
Arrays
Un array es un objeto de elisp que tiene una secuencia de espacios donde almacenar otros objetos Lisp. En un array, puesto que los elementos se almacenan de forma secuencial, el tiempo de acceso a cada uno de esos elementos es constante. Como podemos ver en el gráfico anterior, los vectores y las cadenas son dos tipos especiales de array.
Las funciones más socorridas en conjuntos de datos de tipo array son las de obtener o modificar un elemento:
(aref conjunto índice) (aset conjunto índice valor)
Cadenas
Una cadena de texto es una secuencia de caracteres, como podríamos definir como array de caracteres. Podríamos definir una cadena por ejemplo como:
(setq cadena (string ?H ?o ?l ?a)) ; ==> "Hola" (substring cadena 0 2) ; ==> "Ho" (substring cadena -4 -2) ; ==> "Ho" (string= "Hola" cadena) ; ==> t (string= "hola" cadena) ; ==> nil (aref cadena 3) ; ==> 97 -- ?a (aset cadena 3 ?o) ; ==> 111 -- cadena == "Holo"
Como se ve en el ejemplo, se pueden acceder a los caracteres que forman una cadena por su posición. Si comenzamos a contar la posición desde el inicio, los números de índice son positivos. Si comenzamos por el final, los números serán negativos.
Otra forma muy socorrida de conseguir cadenas bien formadas son las cadenas con formato. Suelen utilizarse para mostrar mensajes de aviso dando formato legible a nuestros datos. Por ejemplo:
(format "El valor del márgen derecho es %d." fill-column)
Los valores que se pueden utilizar para ser sustituidos.
%s- será reemplazada por una cadena.
%o- lo sustituye un número entero en base octal.
%d- lo sustituye un número entero en base decimal.
%x- lo sustituye un número entero en base hexadecimal.
%e- lo sustituye un número en notación exponencial.
%f- lo sustituye un número decimal.
Hay más comodines para dar formatos a los datos, pero esos son los más habituales y los más usados, pues son los correspondientes a mostrar cadenas y números.
Vectores
Un vector es básicamente un array que puede contener cualquier tipo de objetos Lisp en su interior. Para distinguirlo claramente de las listas, se utilizan los corchetes en la notación. Por ejemplo:
(setq mi-vector [1 dos '(tres) "cuatro" [cinco]])
Como se puede observar, los vectores, como los números y las cadenas, se consideran datos estáticos para la evaluación, es decir, cuando Lisp los evalúa el valor devuelto es el mismo vector.
structs
Un struct es tipo de datos definido por el usuario. Mejor, lo vemos
con un ejemplo. Voy a imaginar que quiero definir, a bote pronto y no
con mucho arte, una estructura que albergue datos sobre cuentas:
(cl-defstruct cuenta id balance) ; ==> cuenta (setq a (make-cuenta :id 7 :balance 17.12)) ; ==> #s(cuenta 7 17.12) (cuenta-id a) ; ==> 7 (setf (cuenta-balance a) 0) ; ==> 0 -- cuenta == #s(cuenta 7 0)
En la definición he utilizado la macro cl-defstruct. Internamente,
un struct es muy similar a un array, sin embargo, viene aderezado,
como se puede ver en el ejemplo de funciones automágicas que nos
permiten acceder a los campos del registro.
 2012 -
2012 - 